
In my previous post I challenged you to solve this problem, which essentially asks how many distinct binary tree shapes are created when we take lists of numbers and build a tree from each by repeated binary search tree insertion.
Incidentally, this problem was from the 2016 ICPC world finals (probably one of the easiest ICPC world finals problems ever!).
Several commenters solved it, and all with essentially the same solution. First we need to build some binary search trees by repeated insertion, which we can do by creating a binary tree type and insertion function and then doing some left folds over the input lists. Next, we need to classify the resulting trees by their shape. One obvious method would be to write a function which compares two binary trees to see if they have the same shape; use nubBy to remove duplicates; then count how many trees remain. This would take 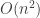
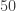
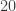
However, there’s a different solution which is both asymptotically faster and less code! The key idea is that if we make the Tree type polymorphic, and an instance of Functor (by writing our own instance, or, even better, using the DeriveFunctor extension), then after building the trees we can turn them into literal tree shapes by replacing the values they contain with (). Moreover, since GHC can also derive an Ord instance for our Tree type, we can then count the distinct tree shapes in 
sort, group, and length, or by throwing them all into a Set and asking for its size.
Here’s my solution:
{-# LANGUAGE DeriveFunctor #-}
import Control.Arrow
import Data.List
main = interact $
lines >>> drop 1 >>> map (words >>> map read) >>> solve >>> show
solve :: [[Int]] -> Int
solve = map (foldl' (flip ins) Empty >>> (() <$)) >>> sort >>> group >>> length
-- or: >>> S.fromList >>> S.size
data Tree a = Empty | Node a (Tree a) (Tree a)
deriving (Show, Eq, Ord, Functor)
ins :: Ord a => a -> Tree a -> Tree a
ins a Empty = Node a Empty Empty
ins a (Node x l r)
| a < x = Node x (ins a l) r
| otherwise = Node x l (ins a r)Honestly I’m not sure what the nicest way to solve this problem in something like Java or C++ would be. In Java, I suppose we would have to make a class for trees, implement equals and compareTo methods which compare trees by shape, and then put all the trees in a TreeSet; or else we could implement hashCode instead of compareTo and use a HashSet. The thing that makes the Haskell solution so much nicer is that the compiler writes some of the code for us, in the form of derived Functor and Ord instances.
For Friday, I invite you to solve Subway Tree System, a nifty problem which is more difficult but has some similar features!


The two important lines in my solution were:
data Subway = Subway [Subway] deriving (Show, Ord, Eq)
canonical (Subway xs) = Subway $ sort (map canonical xs)
Everything else was wrangling data in and out.
Nice! As you’ll see in my post tomorrow, I chose a data representation that did the canonicalization for me automatically. But actually I think yours is simpler!
Thanks. I don’t know exactly what the canonical form is, as I don’t know what the derived order of Subway is.
Actually, the third important line was:
parseSubway = Subway (string “0” *> many parseSubway <* string "1")
which *almost* parses the input strings properly (I have to wrap the strings in a "0" and "1" to get it to work).
Thanks for the hint! I implemented my own `Ord` instance, and used a similar approach to implement my own `Eq` instance, but something didn’t work and my program failed the second trial on kattis.
With your hint my program passed!
Here’s a gist to my solution: https://gist.github.com/blaisepascal/d1a5043e178f982f4484d3c188b4a634
These are fun!I spent most of my time figuring out how to build the tree from the traversal given. I started with a continuation-passing style solution, but as usual that hurt my brain a lot, so I switched to using a Zipper while folding over the list of steps. That worked out quite nicely!
data Zipper a = Zipper { focus :: a, up :: Maybe (Zipper a) }
data Tree a = Tree a [Tree a]
deriving (Show, Ord, Eq)
insert :: [Int] -> Tree Int
insert xs =
let (Zipper result _) = foldl go (Zipper (Tree (-1) []) Nothing) xs
in result
where
go :: Zipper (Tree Int) -> Int -> Zipper (Tree Int)
go (Zipper focus (Just (Zipper (Tree a leaves) up))) 1 = Zipper (Tree a (focus : leaves)) up
go zipper@(Zipper focus Nothing) 1 = zipper
go zipper@(Zipper focus@(Tree d _) up) _ = Zipper (Tree (d – 1) []) (Just zipper)
My full solution is at https://repl.it/@m4dc4p/Subway-Tree
It pains me to look at it, but it passed Kattis…
import Data.List (foldl', sort) import Data.Tree (Tree(..), drawTree, levels) mkTree :: [Char] -> Tree Int mkTree = head . foldl' step [Node 0 []] where step ns '0' = Node 0 [] : ns step (n@(Node i _) : Node i' cs' : ns) '1' = Node (1+i+i') (n : cs') : ns -- ugh canon :: Tree Int -> [[Int]] canon = sort . map sort . levels same :: Tree Int -> Tree Int -> Bool same t0 t1 = canon t0 == canon t1I’m dubious about the canon function in my solution. I suspect a better approach might be to define my own Tree type whose nodes store their children in some ordered container, then “same” becomes just an equality check. But, it’s bedtime…
My solution : https://gist.github.com/abailly/0828481962463ef64a840b14278f6ae5
Don’t like it much, there has to be a better way.
Thanks a lot Brent, this is fun!
:)
My solution: https://gist.github.com/abailly/0828481962463ef64a840b14278f6ae5 Not very elegant I am afraid, I was stuck in the tree reconstruction from the depth-first traversal.
Pingback: Competitive programming in Haskell: building unordered trees | blog :: Brent -> [String]
My solution is more pedagogical. It uses zippers and a hylomorphism. source.
Ooo this is exactly how I solved it! I suddenly don’t feel like a Haskell outsider.
Welcome! =)
In C++, I would have either grouped them using a simple “hasSameStructure” function (for smaller constraints) or used a hashing function to hash the trees (larger constraints).
Ah, a hashing function is a nice idea. So you mean you would specifically combine hashes of subtrees using a commutative and associative operation (e.g. adding) so you would get the same hash no matter their order?
Oh wait, never mind I was thinking of the other problem!
Pingback: Resumen de lecturas compartidas durante mayo de 2020 | Vestigium