
In my previous post, I challenged you to solve Zapis. In this problem, we are given a sequence of opening and closing brackets (parens, square brackets, and curly braces) with question marks, and have to compute the number of different ways in which the question marks could be replaced by brackets to create valid, properly nested bracket sequences.
For example, given (??), the answer is 4: we could replace the question marks with any matched pair (either (), [], or {}), or we could replace them with )(, resulting in ()().
An annoying aside
One very annoying thing to mention about this problem is that it requires us to output the last 5 digits of the answer. At first, I interpreted that to mean “output the answer modulo 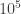

2; but if the answer is 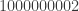
00002, not 2! So simply computing the answer modulo Integer and then literally show the last 5 digits.
A recurrence
Now, how to compute the answer? For this kind of problem the first step is to come up with a recurrence. Let ![s[0 \dots n-1]](https://s0.wp.com/latex.php?latex=s%5B0+%5Cdots+n-1%5D&bg=ffffff&fg=333333&s=0&c=20201002)
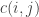
![s[i \dots j-1]](https://s0.wp.com/latex.php?latex=s%5Bi+%5Cdots+j-1%5D&bg=ffffff&fg=333333&s=0&c=20201002)
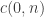


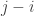
since the empty string always counts as properly nested.
if
Otherwise, ![s[i]](https://s0.wp.com/latex.php?latex=s%5Bi%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![s[i+1]](https://s0.wp.com/latex.php?latex=s%5Bi%2B1%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![s[i+3]](https://s0.wp.com/latex.php?latex=s%5Bi%2B3%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![s[i+5]](https://s0.wp.com/latex.php?latex=s%5Bi%2B5%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![s[j-1]](https://s0.wp.com/latex.php?latex=s%5Bj-1%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![s[k]](https://s0.wp.com/latex.php?latex=s%5Bk%5D&bg=ffffff&fg=333333&s=0&c=20201002)



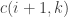
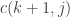
![c(i,j) = \begin{cases} 1 & i = j \\ 0 & i \not \equiv j \pmod 2 \\ \displaystyle \sum_{k \in [i+1, i+3, \dots, j-1]} m(s[i], s[k]) \cdot c(i+1,k) \cdot c(k+1,j) & \text{otherwise} \end{cases}](https://s0.wp.com/latex.php?latex=c%28i%2Cj%29+%3D+%5Cbegin%7Bcases%7D+1+%26+i+%3D+j+%5C%5C+0+%26+i+%5Cnot+%5Cequiv+j+%5Cpmod+2+%5C%5C+%5Cdisplaystyle+%5Csum_%7Bk+%5Cin+%5Bi%2B1%2C+i%2B3%2C+%5Cdots%2C+j-1%5D%7D+m%28s%5Bi%5D%2C+s%5Bk%5D%29+%5Ccdot+c%28i%2B1%2Ck%29+%5Ccdot+c%28k%2B1%2Cj%29+%26+%5Ctext%7Botherwise%7D+%5Cend%7Bcases%7D&bg=ffffff&fg=333333&s=0&c=20201002)
where 


How do we come up with such recurrences in the first place? Unfortunately, Haskell doesn’t really make this any easier—it requires some experience and insight. However, what we can say is that Haskell makes it very easy to directly code a recurrence as a recursive function, to play with it and ensure that it gives correct results for small input values.
A naive solution
To that end, if we directly code up our recurrence in Haskell, we get the following naive solution:
import Control.Arrow
import Data.Array
main = interact $ lines >>> last >>> solve >>> format
format :: Integer -> String
format = show >>> reverse >>> take 5 >>> reverse
solve :: String -> Integer
solve str = c (0,n)
where
n = length str
s = listArray (0,n-1) str
c :: (Int, Int) -> Integer
c (i,j)
| i == j = 1
| even i /= even j = 0
| otherwise = sum
[ m (s!i) (s!k) * c (i+1,k) * c (k+1,j)
| k <- [i+1, i+3 .. j-1]
]
m '(' ')' = 1
m '[' ']' = 1
m '{' '}' = 1
m '?' '?' = 3
m b '?' | b `elem` "([{" = 1
m '?' b | b `elem` ")]}" = 1
m _ _ = 0This solution is correct, but much too slow—it passes the first four test cases but then fails with a Time Limit Exceeded error. In fact, it takes exponential time in the length of the input string, because it has a classic case of overlapping subproblems. Our goal is to compute the same function, but in a way that is actually efficient.
Dynamic programming, aka memoizing recurrences
I hate the name “dynamic programming”—it conveys zero information about the thing that it names, and was essentially invented as a marketing gimmick. Dynamic programming is really just memoizing recurrences in order to compute them more efficiently. By memoizing we mean caching some kind of mapping from input to output values, so that we only have to compute a function once for each given input value; on subsequent calls with a repeated input we can just look up the corresponding output. There are many, many variations on the theme, but memoizing recurrences is really the heart of it.
In imperative languages, dynamic programming is often carried out by filling in tables via nested loops—the fact that there is a recurrence involved is obscured by the implementation. However, in Haskell, our goal will be to write code that is as close as possible to the above naive recursive version, but still actually efficient. Over the next few posts we will discuss several techniques for doing just that.
- In part 1, we will explore the basic idea of using lazy, recursive, immutable arrays (which we have already seen in a previous post).
- In part 2, we will use ideas from Conal Elliot’s
MemoTriepackage (and ultimately from a paper by Ralf Hinze) to clean up the code and make it a lot closer to the naive version. - This post contains a couple challenge problems that can’t quite be solved using the techniques in the previous posts.
- At some point perhaps we’ll discuss how to memoize functions with infinite (or just very large) domains.
- There may very well end up being more parts… we’ll see where it ends up!
Along the way I’ll also drop more links to relevant background. This will ultimately end up as a chapter in the book I’m slowly writing, and I’d like to make it into the definitive reference on dynamic programming in Haskell—so any thoughts, comments, links, etc. are most welcome!


For when you want to mix dynamic programming with a fixed-point analysis, then you might enjoy my https://hackage.haskell.org/package/rec-def library, if you haven’t seen it.
Also see my blog posts about it:
https://www.joachim-breitner.de/blog/792-More_recursive_definitions
https://www.joachim-breitner.de/blog/793-rec-def__Behind_the_scenes
https://www.joachim-breitner.de/blog/794-rec-def__Program_analysis_case_study
https://www.joachim-breitner.de/blog/795-rec-def__Dominators_case_study
https://www.joachim-breitner.de/blog/796-rec-def__Minesweeper_case_study
Yes, very cool! I will have to think whether I have ever seen a competitive programming problem where this could be applied. If you wanted to extract the core functionality of rec-def into a single module, appropriate for copy-pasting into a solution submitted to a site like Open Kattis, how much code would there be?
Hmm, I’m unsure. Depends a bit on whether you need just the set function or also bools. For those example where you need sets (which are probably the typical reachability ones) one could probably have a mini-rec-def snippet. Also, likely thread safety isn’t that much of a concern, which simplifies the problem.
Maybe if you come across something that smells like this, we can give it a shot.
Pingback: Dynamic programming in Haskell: lazy immutable arrays | blog :: Brent -> [String]
A random memory: The book “Algorithms: A Functional Programming Approach” [1] by Fethi Rabhi and Guy Lapalme uses Haskell as its implementation language, and has a chapter on dynamic programming. It’s from 1999 and it uses the table method.
[1] https://www.iro.umontreal.ca/~lapalme/Algorithms-functional.html
I wasn’t aware of that, thanks for the reference!
Pingback: Dynamic programming in Haskell: automatic memoization | blog :: Brent -> [String]
Pingback: Competitive Programming in Haskell: two more DP challenges | blog :: Brent -> [String]