
Time for me to reveal the example I had in mind that led to the generalization in my previous post. Thanks for all the interesting comments: it seems like there are some interesting connections to be explored (e.g. to the algebra of graphs, formal group laws, …?)!
This is a literate Haskell post; download it and play along in ghci! (Note it requires GHC 8.6 since I couldn’t resist making use of DerivingVia…)
> {-# LANGUAGE DefaultSignatures #-}
> {-# LANGUAGE FlexibleInstances #-}
> {-# LANGUAGE MultiParamTypeClasses #-}
> {-# LANGUAGE DerivingStrategies #-}
> {-# LANGUAGE GeneralizedNewtypeDeriving #-}
> {-# LANGUAGE DerivingVia #-}
> {-# LANGUAGE TypeApplications #-}
> {-# LANGUAGE ScopedTypeVariables #-}
>
> import Data.Semigroup
> import Data.Coerce
Consider a sequence of integers 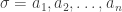


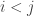
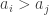
![\sigma = [3,5,1,4,2]](https://s0.wp.com/latex.php?latex=%5Csigma+%3D+%5B3%2C5%2C1%2C4%2C2%5D&bg=ffffff&fg=333333&s=0&c=20201002)
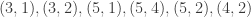
![[2,2,1]](https://s0.wp.com/latex.php?latex=%5B2%2C2%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002)


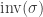
One way to think about the inversion count is as a measure of how far away the sequence is from being sorted. In particular, bubble sort will make precisely 
The obvious brute-force algorithm to count inversions is to use two nested loops to enumerate all possible pairs of elements, and increment a counter each time we discover a pair which is out of order. This clearly takes 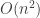
It turns out the (generally well-known) answer is yes, using a variant of mergesort. The trick is to generalize to counting inversions and sorting the sequence at the same time. First split the sequence in half, and recursively sort and count the inversions in each half. Any inversion in the original sequence must either be entirely contained in one of the two halves (these will be counted by the recursive calls), or have one endpoint in the left half and one in the right. One key observation at this point is that any inversion with one endpoint in each half will still be an inversion even after independently sorting the two halves. The other key observation is that we can merge the two sorted subsequences and count inversions between them in linear time. Use the usual two-finger algorithm for merging two sorted sequences; each time we take an element from the right subsequence, it’s because it is less than all the remaining elements in the left subsequence, but it was to the right of all of them, so we can add the length of the remaining left subsequence to the inversion count. Intuitively, it’s this ability to count a bunch of inversions in one step which allows this algorithm to be more efficient, since any algorithm which only ever increments an inversion counter is doomed to be
Here’s some Haskell code implementing this sorted-merge-and-inversion-count. We have to be a bit careful because we don’t want to call length on the remaining sublist at every step (that would ruin the asymptotic performance!), so we precompute the length and pass along the length of the left subsequence as an extra parameter which we keep up-to-date as we recurse.
> -- Precondition: the input lists are sorted.
> -- Output the sorted merge of the two lists, and the number of pairs
> -- (a,b) such that a \in xs, b \in ys with a > b.
> mergeAndCount :: Ord a => [a] -> [a] -> ([a], Int)
> mergeAndCount xs ys = go xs (length xs) ys
> -- precondition/invariant for go xs n ys: n == length xs
> where
> go [] _ ys = (ys, 0)
> go xs _ [] = (xs, 0)
> go (x:xs) n (y:ys)
> | x <= y = let (m, i) = go xs (n-1) (y:ys) in (x:m, i)
> | otherwise = let (m, i) = go (x:xs) n ys in (y:m, i + n)
>
> merge :: Ord a => [a] -> [a] -> [a]
> merge xs ys = fst (mergeAndCount xs ys)
>
> inversionsBetween :: Ord a => [a] -> [a] -> Int
> inversionsBetween xs ys = snd (mergeAndCount xs ys)
Do you see how this is an instance of the sparky monoid construction in my previous post? 


We have to verify that this satisfies the laws: let 
-
, that is,
a `inversionsBetween` [] = 0. This is true since there are never any inversions between.
-
a `inversionsBetween` (a1 `merge` a2) == (a `inversionsBetween` a1) + (a `inversionsBetween` a2). This is also true sincea1 `merge` a2contains the same elements asa1anda2: any inversion betweenaanda1 `merge` a2will be an inversion betweenaanda1, or betweenaanda2, and vice versa. The same reasoning shows that(a1 `merge` a2) `inversionsBetween` a == (a1 `inversionsBetween` a) + (a2 `inversionsBetween` a).
Note that a1 and a2 precisely iff they are not an inversion between a2 and a1. Note also that
So let’s see some more Haskell code to implement the entire algorithm in a nicely modular way. First, let’s encode sparky monoids in general. The Sparky class is for pairs of types with a spark operation. As we saw in the example above, sometimes it may be more efficient to compute 

> class Sparky a b where
The basic spark operation, with a default implementation that projects the result out of the prodSpark method.
> (<.>) :: a -> a -> b
> a1 <.> a2 = snd (prodSpark a1 a2)
prodSpark does the monoidal product and spark at the same time, with a default implementation that just does them separately.
> prodSpark :: a -> a -> (a,b)
> default prodSpark :: Semigroup a => a -> a -> (a,b)
> prodSpark a1 a2 = (a1 <> a2, a1 <.> a2)
Finally we can specify that we have to implement one or the other of these methods.
> {-# MINIMAL (<.>) | prodSpark #-}
Sparked a b is just a pair type, but with Semigroup and Monoid instances that implement the sparky product.
> data Sparked a b = S { getA :: a, getSpark :: b }
> deriving Show
>
> class Semigroup a => CommutativeSemigroup a
> class (Monoid a, CommutativeSemigroup a) => CommutativeMonoid a
>
> instance (Semigroup a, CommutativeSemigroup b, Sparky a b) => Semigroup (Sparked a b) where
> S a1 b1 <> S a2 b2 = S a' (b1 <> b2 <> b')
> where (a', b') = prodSpark a1 a2
>
> instance (Monoid a, CommutativeMonoid b, Sparky a b) => Monoid (Sparked a b) where
> mempty = S mempty mempty
Now we can make instances for sorted lists under merge…
> newtype Sorted a = Sorted [a]
> deriving Show
>
> instance Ord a => Semigroup (Sorted a) where
> Sorted xs <> Sorted ys = Sorted (merge xs ys)
> instance Ord a => Monoid (Sorted a) where
> mempty = Sorted []
>
> instance Ord a => CommutativeSemigroup (Sorted a)
> instance Ord a => CommutativeMonoid (Sorted a)
…and for inversion counts.
> newtype InvCount = InvCount Int
> deriving newtype Num
> deriving (Semigroup, Monoid) via Sum Int
>
> instance CommutativeSemigroup InvCount
> instance CommutativeMonoid InvCount
Finally we make the Sparky (Sorted a) InvCount instance, which is just mergeAndCount (some conversion between newtypes is required, but we can get the compiler to do it automagically via coerce and a bit of explicit type application).
> instance Ord a => Sparky (Sorted a) InvCount where
> prodSpark = coerce (mergeAndCount @a)
And here’s a function to turn a single a value into a sorted singleton list paired with an inversion count of zero, which will come in handy later.
> single :: a -> Sparked (Sorted a) InvCount
> single a = S (Sorted [a]) 0
Finally, we can make some generic infrastructure for doing monoidal folds. First, Parens a encodes lists of a which have been explicitly associated, i.e. fully parenthesized:
> data Parens a = Leaf a | Node (Parens a) (Parens a)
> deriving Show
We can make a generic fold for Parens a values, which maps each Leaf into the result type b, and replaces each Node with a binary operation:
> foldParens :: (a -> b) -> (b -> b -> b) -> Parens a -> b
> foldParens lf _ (Leaf a) = lf a
> foldParens lf nd (Node l r) = nd (foldParens lf nd l) (foldParens lf nd r)
Now for a function which splits a list in half recursively to produce a balanced parenthesization.
> balanced :: [a] -> Parens a
> balanced [] = error "List must be nonempty"
> balanced [a] = Leaf a
> balanced as = Node (balanced as1) (balanced as2)
> where (as1, as2) = splitAt (length as `div` 2) as
Finally, we can make a balanced variant of foldMap: instead of just mapping a function over a list and then reducing with mconcat, as foldMap does, it first creates a balanced parenthesization for the list and then reduces via the given monoid. This will always give the same result as foldMap due to associativity, but in some cases it may be more efficient.
> foldMapB :: Monoid m => (e -> m) -> [e] -> m
> foldMapB leaf = foldParens leaf (<>) . balanced
Let’s try it out!
λ> :set +s
λ> getSpark $ foldMap single [3000, 2999 .. 1 :: Int]
Sum {getSum = 4498500}
(34.94 secs, 3,469,354,896 bytes)
λ> getSpark $ foldMapB single [3000, 2999 .. 1 :: Int]
Sum {getSum = 4498500}
(0.09 secs, 20,016,936 bytes)Empirically, it does seem that we are getting quadratic performance with normal foldMap, but 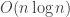
foldMapB. We can verify that we are getting the correct inversion count in either case, since we know there should be 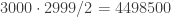


Awesome! :)
I guess many divide and conquer algorithms can be expressed similarly. A couple of examples that come to mind:
1) Finding a closest pair of points on a plane: https://en.wikipedia.org/wiki/Closest_pair_of_points_problem — here A are sorted sets of points with union, B are numbers with the minimum operation, and the spark operation corresponds to finding the closest pair of points between two given sets.
2) Finding the longest substring repetition: https://cp-algorithms.com/string/main_lorentz.html — here A are strings with concatenation, B are numbers with the maximum operation, and the spark operation corresponds to finding the longest repetition crossing the boundary of two strings.
2) seems to have similar structure to the `minNub` algorithm https://books.google.co.il/books?id=ZQJnYoAmw6gC&lpg=PA67&ots=7B9GABUutD&dq=minNub%20haskell&pg=PA64#v=onepage&q=minNub&f=false – thanks for the insight!
In general, the examples given seem to suggest that this “Sparky” scheme generalizes “linearly dependent” divide-and-conquer algorithms – functions `f` such that `f (xy)=f xf’ y (g x)`. I will be working out whether this suggestion is correct later.
A tiny refactor suggestion: Depending on which of `xs` and `ys is longer, it might be more efficient to – instead of precomputing `length xs` and decrementing – keep track of how many elements of `ys` have already been emitted and adding that to the sum of inversions for each emission of an element of `xs`.
… I see my <> signs have been stripped. Oops.
Meant `f (x<>y)=f x<> f’ y (g x)`.
Ah, good point re: refactoring. It was only after writing this post that it dawned on me that the situation is completely symmetric, and we can count inversions either when taking an element out of ys (add the number of remaining elements in xs) or when taking an element out of xs (add the number of elements from ys that have already been emitted). The difference basically comes down to adding up the number of dots in a Ferrers diagram by rows or by columns.
Ah, nice examples, thanks!
The algorithm you describe reminds me a bunch of the efficient maximum segment sum algorithm, and indeed I introduced a “scan” type in my 2014 “buildable” that’s not developed directly as a monoid, but as an accumulator of a monoidal action, but nonetheless resembles the construction of your sparky monoids: http://gbaz.github.io/slides/buildable2014.pdf
I think this relates to zygomorphisms but I have not the brain cells to put the connections together at this hour.
Formal group laws are also in general a rich set of structures for generating interesting monoids, with potential connections to the algebra of data types, but I’ve never worked out the details of what one might do with them in an FP context. I know of them through their connection to elliptic curves and cohomology theories — but it turns out I guess that they have combinatorial uses as well? https://digital.lib.washington.edu/researchworks/handle/1773/36757
Thanks for the links! Yes, these seem like interesting connections to explore further.
Pingback: Counting inversions via rank queries | blog :: Brent -> [String]