
In my last competitive programming post, I challenged you to solve Please, Go First. In that problem, we are presented with a hypothetical scenario with people waiting in a queue for a ski lift. Each person is part of a friend group (possibly just themselves), but friend groups are not necessarily consecutive in line; when someone gets to the top they will wait for the last person in their friend group to arrive before skiing. We are asked to consider how much waiting time could be saved if people start letting others go ahead of them in line as long as it doesn’t cost them any waiting time and decreases the waiting time for the others.
There is actually a bit of ambiguity that we need to resolve first; to be honest, it’s not the most well-written problem statement. Consider this scenario, with three people in group 


Consider the person labelled 
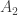
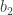
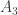


The solution idea
It took me an embarrassingly long time to come up with the following key insight: after doing this process as much as possible, I claim that (1) all the friends within each friend group will be consecutive, and (2) the groups will be sorted by the original position of the last person in each group. To see why claim (2) is true, note that whenever someone is last in their friend group, moving backward in the line always increases their waiting time; so any two people who are both last in their friend group will never pass each other, since it would make the waiting time worse for the one who moves backward. That means the people who are last in their friend group will always remain in the same relative order. As for claim (1), I thought about it for a while and am so far unable to come up with a short, convincing proof, though I still believe it is true (and my solution based on it was accepted). If anyone has a good way to show why this must be true, I’d love to hear about it in the comments.
My second key insight is that the total amount of time saved for a given friend group depends only on (1) how many people are in the group and (2) how many places the last person in the group got to move up (although there are other ways to solve the problem; more below). In particular, the total time saved for the group will be the product of these two numbers, times five minutes. It’s irrelevant how many places someone moves if they are not last in their group, because they have to wait until that last person arrives, and it makes no difference if they do their waiting at the top or bottom of the mountain.
My solution
So here’s my solution, based on the above insights. First, let’s set up the main pipeline to read the input, solve each test case, and produce the output.
main = C.interact $
runScanner (numberOf (int *> str)) >>> map (solve >>> showB) >>> C.unlinesshowB is just a utility function I’ve recently added to my solution template which calls show and then converts the result to a ByteString using pack.
For a given test case, we need to first do a pass through the lift queue in order to accumulate some information about friend groups: for each group, we need to know how big it is, as well as the index of the last member of the group. In an imperative language, we would make accumulator variables to hold this information (probably two maps, aka dictionaries), and then iterate through the queue, imperatively updating the accumulator variables for each item. We can translate that approach more or less mechanically into Haskell, by having an update function that takes a single item and a tuple of accumulators as input, and returns a new tuple of accumulators as output. This is the approach taken by Aaron Allen, and sometimes that’s the best way to do something like this. However, in this particular scenario—looping over a list and accumulating some information—the accumulators are often monoidal, which gives us much nicer tools to work with, such as foldMap and Data.Map.fromListWith (<>).
We’ll make a type Group to represent the needed information about a friend group: the number of people and the index of the last person. We can use DerivingVia to create an appropriate Semigroup instance for it (in this case we actually don’t need Monoid since there is no such thing as an empty group). Note that we use First Int instead of the expected Last Int; this is explained below.
newtype Group = Group { unGroup :: (Int, Int) }
deriving Semigroup via (Sum Int, First Int)
deriving ShowNow we can write the code to calculate the total time save for a given starting queue.
solve :: ByteString -> Int
solve (C.unpack -> queue) = timeSaved
whereWe first map over the queue and turn each item into a singleton Group (imap is a utility to do an indexed map, with type (Int -> a -> b) -> [a] -> [b]); then we use M.fromListWith (<>) to build a Map associating each distinct character to a Group. The Semigroup instance will take care of summing the number of friends and keeping only the last index in each group. Note that fromListWith is implemented via a left fold, which explains why we needed to use First Int instead of Last Int: the list items will actually be combined in reverse order. (Alternatively, we could use Last Int and M.fromListWith (flip (<>)); of course, this is only something we need to worry about when using a non-commutative Semigroup).
groupInfo :: Map Char Group
groupInfo = queue >$> imap (\i c -> (c, Group (1, i))) >>> M.fromListWith (<>)Now we can sort the queue by index of the last member of each friend group, producing its final form:
sortedQueue = sortOn ((groupInfo!) >>> unGroup >>> snd) queueComputing the total time saved is now just a matter of figuring out how much each last friend moved and summing the time save for each friend group:
timeSaved = sortedQueue >$> zip [0 :: Int ..] -- final positions
>>> groupBy ((==) `on` snd) -- put groups together
>>> map (last >>> timeSaveForGroup) >>> sum
-- get the time save based on the last person in each group
timeSaveForGroup (i,c) = 5 * size * (idx - i)
where
Group (size, idx) = groupInfo!cThis is not the fastest way to solve the problem—in fact, my solution is slowest of the five Haskell solutions so far!—but I wanted to illustrate this technique of accumulating over an array using a Semigroup and M.fromListWith. foldMap can be used similarly when we need just a single result value rather than a Map of some sort.
Other solutions
Several people linked to their own solutions. I already mentioned Aaron Allen’s solution above. Anurudh Peduri’s solution works by computing the initial and final wait time for each group and subtracting; notably, it simply sorts the groups alphabetically, not by index of the final member of the group. I don’t quite understand it, but I think this works because the initial and final wait times would change by the same amount when permuting the groups in line, so ultimately this cancels out.
Tim Put’s solution is by far the fastest (and, in my opinion, the cleverest). For each friend in a friend group, it computes the number of people in other friend groups who stand between them and the last person in their group (using a clever combination of functions including ByteString.elemIndices). Each such person represents a potential time save of 5 minutes, all of which will be realized once the groups are all consecutive. Hence all we have to do is sum these numbers and multiply by 5. It is instructive thinking about why this works. It does not compute the actual time saved by each group, just the potential time save represented by each group. That potential time save might be realized by the group itself (if the last person in the group gets to move up) or by a different group (if someone in the group lets others go ahead of them). Ultimately, though, it does not matter how much time is saved by each group, only the total amount of time saved.
Next time: Purple Rain
For next time, I invite you to solve Purple Rain. This problem has a solution which is “well known” in competitive programming (if you need a hint, ybbx hc Xnqnar’f Nytbevguz); the challenge is to translate it into idiomatic (and, ideally, reusable) Haskell.


For your first claim, number the groups by their position in your final result, i.e. by the position of their last member among all last members. For each arrangement $A$ of the queue, let $d(A)$ be the number of displacements, i.e. for each person in the queue, count how many members of higher-numbered groups are in front of them and sum these counts. If $d(A)$ is zero, we’re done. So assume that $d(A) > 0$. I claim that there are two consecutive people in the queue such that the first has a higher group number than the second. (Considering the contrapositive, this is obvious.) These two people can swap, which doesn’t increase any groups wait time but lowers $d(A)$ by one.
Oh, very nice!
Hey, could you tell which package the `(>$>)` and `imap` functions live in? Or are they custom functions you defined?
I defined them as:
“`haskell
imap :: (Int -> a -> b) -> [a] -> [b]
imap f = zipWith f [0..]
(>$>) :: a -> (a -> b) -> b
(>$>) = flip ($)
infixr 1 >$>
“`
Are these correct?
They are custom functions that I defined (I didn’t want to show the entire code because these days I tend to start from a large template with many common imports and utility functions). You have defined them correctly. I declare >$> to be infixl 0, but I don’t think it matters that much.
My submission for purple rain: https://gist.github.com/aaronallen8455/2183578305e37bcadf349b9bc21a2d6d. I tried to make it somewhat reusable.
Please find my solution here: https://github.com/TimPut/KattisProblems/blob/master/purplerain.hs
No terrible cleverness this time around, though the “well known” algorithm should be reusable.
Pingback: Competitive programming in Haskell: Kadane’s algorithm | blog :: Brent -> [String]