
In my last post in this series, we looked at building a small Scanner combinator library for lightweight input parsing. It uses String everywhere, and usually this is fine, but occasionally it’s not.
A good example is the Kattis problem Army Strength (Hard). There are a number of separate test cases; each test case consists of two lines of positive integers which record the strengths of monsters in two different armies. Supposedly the armies will have a sequence of battles, where the weakest monster dies each time, with some complex-sounding rules about how to break ties. It sounds way more complicated than it really is, though: a bit of thought reveals that to find out who wins we really just need to see which army’s maximum-strength monster is strongest.
So our strategy for each test case is to read in the two lists of integers, find the maximum of each list, and compare. Seems pretty straightforward, right? Something like this:
import Control.Arrow
import Data.List.Split
main = interact $
lines >>> drop 1 >>> chunksOf 4 >>>
map (drop 2 >>> map (words >>> map read) >>> solve) >>>
unlines
solve :: [[Int]] -> String
solve [gz, mgz] = case compare (maximum gz) (maximum mgz) of
LT -> "MechaGodzilla"
_ -> "Godzilla"Note I didn’t actually use the Scanner abstraction here, though I could have; it’s actually easier to just ignore the numbers telling us how many test cases there are and the length of each line, and just split up the input by lines and go from there.
This seems straightforward enough, but sadly, it results in a Time Limit Exceeded (TLE) error on the third of three test cases. Apparently this program takes longer than the allowed 1 second. What’s going on?
If we look carefully at the limits for the problem, we see that there could be up to 50 test cases, each test case could have two lists of length 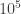
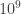
String has a lot of overhead: each character gets its own cons cell; breaking the input into lines and words requires traversing over these cons cells one by one. We need a representation with less overhead.
Now, if this were a real application, we would reach for Text, which is made for representing textual information and can correctly handle unicode encodings and all that good stuff. However, this isn’t a real application: competitive programming problems always limit the input and output strictly to ASCII, so characters are synonymous with bytes. Therefore we will commit a “double no-no”: not only are we going to use ByteString to represent text, we’re going to use Data.ByteString.Lazy.Char8 which simply assumes that each 8 bits is one character. As explained in a previous post, however, I think this is one of those things that is usually a no-no but is completely justified in this context.
Let’s start by just replacing some of our string manipulation with corresponding ByteString versions:
import Control.Arrow
import qualified Data.ByteString.Lazy.Char8 as C
import Data.List.Split
main = C.interact $
C.lines >>> drop 1 >>> chunksOf 4 >>>
map (drop 2 >>> map (C.words >>> map (C.unpack >>> read)) >>> solve) >>>
C.unlines
solve :: [[Int]] -> C.ByteString
solve [gz, mgz] = case compare (maximum gz) (maximum mgz) of
LT -> C.pack "MechaGodzilla"
_ -> C.pack "Godzilla"This already helps a lot: this version is actually accepted, taking 0.66 seconds. (Note there’s no way to find out how long our first solution would take if allowed to run to completion: once it goes over the time limit Kattis just kills the process. So we really don’t know how much of an improvement this is, but hey, it’s accepted!)
But we can do even better: it turns out that read also has a lot of overhead, and if we are specifically reading Int values we can do something much better. The ByteString module comes with a function
readInt :: C.ByteString -> Maybe (Int, C.ByteString)
Since, in this context, we know we will always get an integer with nothing left over, we can replace C.unpack >>> read with C.readInt >>> fromJust >>> fst. Let’s try it:
import Control.Arrow
import qualified Data.ByteString.Lazy.Char8 as C
import Data.List.Split
import Data.Maybe (fromJust)
main = C.interact $
C.lines >>> drop 1 >>> chunksOf 4 >>>
map (drop 2 >>> map (C.words >>> map readInt) >>> solve) >>>
C.unlines
where
readInt = C.readInt >>> fromJust >>> fst
solve :: [[Int]] -> C.ByteString
solve [gz, mgz] = case compare (maximum gz) (maximum mgz) of
LT -> C.pack "MechaGodzilla"
_ -> C.pack "Godzilla"Now we’re talking — this version completes in a blazing 0.04 seconds!
We can take these principles and use them to make a variant of the Scanner module from last time which uses (lazy, ASCII) ByteString instead of String, including the use of the readInt functions to read Int values quickly. You can find it here.


Pingback: Resumen de lecturas compartidas durante octubre de 2019 | Vestigium
Pingback: Competitive programming in Haskell: summer series | blog :: Brent -> [String]
Pingback: Competitive programming in Haskell: topsort via laziness | blog :: Brent -> [String]