
Since I’ve been coaching my school’s ACM ICPC programming team, I’ve been spending a bit of time solving programming contest problems, partly to stay sharp and be able to coach them better, but also just for fun.
I recently solved a problem (using Haskell) that ended up being tougher than I thought, but I learned a lot along the way. Rather than just presenting a solution, I’d like to take you through my thought process, crazy detours and all.
Of course, I should preface this with a big spoiler alert: if you want to try solving the problem yourself, you should stop reading now!
> {-# LANGUAGE GADTs #-}
> {-# LANGUAGE DeriveFunctor #-}
>
> module Brackets where
>
> import Data.List (sort, genericLength)
> import Data.MemoTrie (memo, memo2)
> import Prelude hiding ((++))
The problem
There’s a lot of extra verbiage at the official problem description, but what it boils down to is this:
Find the 

There is a longer description at the problem page, but hopefully a few examples will suffice. A balanced bracketing is a string consisting solely of parentheses, in which opening and closing parens can be matched up in a one-to-one, properly nested way. For example, there are five balanced bracketings of length 
((())), (()()), (())(), ()(()), ()()()
By lexicographically ordered we just mean that the bracketings should be in “dictionary order” where ( comes before ), that is, bracketing 

( and ). As you can verify, the list of length-
A first try
Oh, this is easy, I thought, especially if we consider the well-known isomorphism between balanced bracketings and binary trees. In particular, the empty string corresponds to a leaf, and (L)R (where L and R are themselves balanced bracketings) corresponds to a node with subtrees L and R. So the five balanced bracketings of length

We can easily generate all the binary trees of a given size with a simple recursive algorithm. If 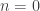
Leaf; otherwise, decide how many nodes to put on the left and how many on the right, and for each such distribution recursively generate all possible trees on the left and right.
> data Tree where
> Leaf :: Tree
> Node :: Tree -> Tree -> Tree
> deriving (Show, Eq, Ord)
>
> allTrees :: Int -> [Tree]
> allTrees 0 = [Leaf]
> allTrees n =
> [ Node l r
> | k <- [0 .. n-1]
> , l <- allTrees ((n-1) - k)
> , r <- allTrees k
> ]
We generate the trees in “left-biased” order, where we first choose to put all 
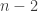


Writing allTrees is easy enough, but it’s definitely not going to cut it: the problem states that we could have up to 

So I immediately launched into writing such a function, but it’s tricky to get right. It involves computing Catalan numbers, and cumulative sums of products of Catalan numbers, and divMod, and… I never did get that function working properly.
The first epiphany
But I never should have written that function in the first place! What I should have done first was to do some simple tests just to confirm my intuition that left-biased tree order corresponds to sorted bracketing order. Because if I had, I would have found this:
> brackets :: Tree -> String
> brackets Leaf = ""
> brackets (Node l r) = mconcat ["(", brackets l, ")", brackets r]
>
> sorted :: Ord a => [a] -> Bool
> sorted xs = xs == sort xs
ghci> sorted (map brackets (allTrees 3))
True
ghci> sorted (map brackets (allTrees 4))
False
As you can see, my intuition actually led me astray! 
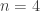

In the top row are the size-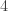
allTrees. You can see it is nice and symmetric: reflecting the list across a vertical line leaves it unchanged. On the bottom row are the same trees, but sorted lexicographically by their bracketings. You can see that the lists are almost the same except the red tree is in a different place. The issue is the length of the left spine: the red tree has a left spine of three nodes, which means its bracketing will begin with (((, so it should come before any trees with a left spine of length 2, even if they have all their nodes in the left subtree (whereas the red tree has one of its nodes in the right subtree).
My next idea was to try to somehow enumerate trees in order by the length of their left spine. But since I hadn’t even gotten indexing into the original left-biased order to work, it seemed hopeless to get this to work by implementing it directly. I needed some bigger guns.
Building enumerations
At this point I had the good idea to introduce some abstraction. I defined a type of enumerations (a la FEAT or data/enumerate):
> data Enumeration a = Enumeration
> { fromNat :: Integer -> a
> , size :: Integer
> }
> deriving Functor
>
> enumerate :: Enumeration a -> [a]
> enumerate (Enumeration f n) = map f [0..n-1]
An Enumeration consists of a size along with a function Integer -> a, which we think of as being defined on [0 .. size-1]. That is, an Enumeration is isomorphic to a finite list of a given length, where instead of explicitly storing the elements, we have a function which can compute the element at a given index on demand. If the enumeration has some nice combinatorial structure, then we expect that this on-demand indexing can be done much more efficiently than simply listing all the elements. The enumerate function simply turns an Enumeration into the corresponding finite list, by mapping the indexing function over all possible indices.
Note that Enumeration has a natural Functor instance, which GHC can automatically derive for us. Namely, if e is an Enumeration, then fmap f e is the Enumeration which first computes the element of e for a given index, and then applies f to it before returning.
Now, let’s define some combinators for building Enumerations. We expect them to have all the nice algebraic flavor of finite lists, aka free monoids.
First, we can create empty or singleton enumerations, or convert any finite list into an enumeration:
> empty :: Enumeration a
> empty = Enumeration (const undefined) 0
>
> singleton :: a -> Enumeration a
> singleton a = Enumeration (\_ -> a) 1
>
> list :: [a] -> Enumeration a
> list as = Enumeration (\n -> as !! fromIntegral n) (genericLength as)
ghci> enumerate (empty :: Enumeration Int)
[]
ghci> enumerate (singleton 3)
[3]
ghci> enumerate (list [4,6,7])
[4,6,7]
We can form the concatenation of two enumerations. The indexing function compares the given index against the size of the first enumeration, and then indexes into the first or second enumeration appropriately. For convenience we can also define union, which is just an iterated version of (++).
> (++) :: Enumeration a -> Enumeration a -> Enumeration a
> e1 ++ e2 = Enumeration
> (\n -> if n < size e1 then fromNat e1 n else fromNat e2 (n - size e1))
> (size e1 + size e2)
>
> union :: [Enumeration a] -> Enumeration a
> union = foldr (++) empty
ghci> enumerate (list [3, 5, 6] ++ empty ++ singleton 8)
[3,5,6,8]
Finally, we can form a Cartesian product: e1 >< e2 is the enumeration of all possible pairs of elements from e1 and e2, ordered so that all the pairs formed from the first element of e1 come first, followed by all the pairs with the second element of e1, and so on. The indexing function divides the given index by the size of e2, and uses the quotient to index into e1, and the remainder to index into e2.
> (><) :: Enumeration a -> Enumeration b -> Enumeration (a,b)
> e1 >< e2 = Enumeration
> (\n -> let (l,r) = n `divMod` size e2 in (fromNat e1 l, fromNat e2 r))
> (size e1 * size e2)
ghci> enumerate (list [1,2,3] >< list [10,20])
[(1,10),(1,20),(2,10),(2,20),(3,10),(3,20)]
ghci> let big = list [0..999] >< list [0..999] >< list [0..999] >< list [0..999]
ghci> fromNat big 2973428654
(((2,973),428),654)
Notice in particular how the fourfold product of list [0..999] has 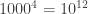
fromNat is basically instantaneous.
Since Enumerations are isomorphic to finite lists, we expect them to have Applicative and Monad instances, too. First, the Applicative instance is fairly straightforward:
> instance Applicative Enumeration where
> pure = singleton
> f <*> x = uncurry ($) <$> (f >< x)
ghci> enumerate $ (*) <$> list [1,2,3] <*> list [10, 100]
[10,100,20,200,30,300]
pure creates a singleton enumeration, and applying an enumeration of functions to an enumeration of arguments works by taking a Cartesian product and then applying each pair.
The Monad instance works by substitution: in e >>= k, the continuation k is applied to each element of the enumeration e, and the resulting enumerations are unioned together in order.
> instance Monad Enumeration where
> return = pure
> e >>= f = union (map f (enumerate e))
ghci> enumerate $ list [1,2,3] >>= \i -> list (replicate i i)
[1,2,2,3,3,3]
Having to actually enumerate the elements of e is a bit unsatisfying, but there is really no way around it: we otherwise have no way to know how big the resulting enumerations are going to be.
Now, that function I tried (and failed) to write before that generates the tree at a particular index in left-biased order? Using these enumeration combinators, it’s a piece of cake. Basically, since we built up combinators that mirror those available for lists, it’s just as easy to write this indexing version as it is to write the original allTrees function (which I’ve copied below for comparison):
allTrees :: Int -> [Tree]
allTrees 0 = [Leaf]
allTrees n =
[ Node l r
| k <- [0 .. n-1]
, l <- allTrees ((n-1) - k)
, r <- allTrees k
]> enumTrees :: Int -> Enumeration Tree
> enumTrees 0 = singleton Leaf
> enumTrees n = union
> [ Node <$> enumTrees (n-k-1) <*> enumTrees k
> | k <- [0 .. n-1]
> ]
(enumTrees and allTrees look a bit different, but actually allTrees can be rewritten in a very similar style:
allTrees :: Int -> [Tree]
allTrees 0 = [Leaf]
allTrees n = concat
[ Node <$> allTrees ((n-1) - k) <*> r <- allTrees k
| k <- [0 .. n-1]
]Doing as much as possible using the Applicative interface gives us added “parallelism”, which in this case means the ability to index directly into a product with divMod, rather than scanning through the results of calling a function on enumerate until we have accumulated the right size. See the paper on the GHC ApplicativeDo extension.)
Let’s try it out:
ghci> enumerate (enumTrees 3)
[Node (Node (Node Leaf Leaf) Leaf) Leaf,Node (Node Leaf (Node Leaf Leaf)) Leaf,Node (Node Leaf Leaf) (Node Leaf Leaf),Node Leaf (Node (Node Leaf Leaf) Leaf),Node Leaf (Node Leaf (Node Leaf Leaf))]
ghci> enumerate (enumTrees 3) == allTrees 3
True
ghci> enumerate (enumTrees 7) == allTrees 7
True
ghci> brackets $ fromNat (enumTrees 7) 43
"((((()())))())"
It seems to work! Though actually, if we try larger values of enumTrees just seems to hang. The problem is that it ends up making many redundant recursive calls. Well… nothing a bit of memoization can’t fix! (Here I’m using Conal Elliott’s nice MemoTrie package.)
> enumTreesMemo :: Int -> Enumeration Tree
> enumTreesMemo = memo enumTreesMemo'
> where
> enumTreesMemo' 0 = singleton Leaf
> enumTreesMemo' n = union
> [ Node <$> enumTreesMemo (n-k-1) <*> enumTreesMemo k
> | k <- [0 .. n-1]
> ]
ghci> size (enumTreesMemo 10)
16796
ghci> size (enumTreesMemo 100)
896519947090131496687170070074100632420837521538745909320
ghci> size (enumTreesMemo 1000)
2046105521468021692642519982997827217179245642339057975844538099572176010191891863964968026156453752449015750569428595097318163634370154637380666882886375203359653243390929717431080443509007504772912973142253209352126946839844796747697638537600100637918819326569730982083021538057087711176285777909275869648636874856805956580057673173655666887003493944650164153396910927037406301799052584663611016897272893305532116292143271037140718751625839812072682464343153792956281748582435751481498598087586998603921577523657477775758899987954012641033870640665444651660246024318184109046864244732001962029120
ghci> brackets $ fromNat (enumTreesMemo 1000) 8234587623904872309875907638475639485792863458726398487590287348957628934765
"((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((()(((()((((()))())(()()()))()(())(())((()((()))(((())()(((((()(((()()))(((()((((()()(())()())(((()))))(((()()()(()()))))(((()((()))(((()())())))())(()()(())(())()(()())))()))((()()))()))()))()(((()))(()))))))())()()()))((())((()))((((())(())))((())))))()))()(())))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))"
That’s better!
A second try
At this point, I thought that I needed to enumerate trees in order by the length of their left spine. Given a tree with a left spine of length 
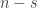
First, we need an enumeration of the partitions of a given 
> kPartitions :: Int -> Int -> Enumeration [Int]
There is exactly one way to partition 
> kPartitions 0 0 = singleton []
We can’t partition anything other than
> kPartitions _ 0 = empty
Otherwise, pick a number 


> kPartitions n k = do
> i <- list [n, n-1 .. 0]
> (i:) <$> kPartitions (n-i) (k-1)
Let’s try it:
ghci> let p43 = enumerate $ kPartitions 4 3
ghci> p43
[[4,0,0],[3,1,0],[3,0,1],[2,2,0],[2,1,1],[2,0,2],[1,3,0],[1,2,1],[1,1,2],[1,0,3],[0,4,0],[0,3,1],[0,2,2],[0,1,3],[0,0,4]]
ghci> all ((==3) . length) p43
True
ghci> all ((==4) . sum) p43
True
ghci> sorted (reverse p43)
True
Now we can use kPartitions to build our enumeration of trees:
> spinyTrees :: Int -> Enumeration Tree
> spinyTrees = memo spinyTrees'
> where
> spinyTrees' 0 = singleton Leaf
> spinyTrees' n = do
>
> -- Pick the length of the left spine
> spineLen <- list [n, n-1 .. 1]
>
> -- Partition the remaining elements among the spine nodes
> bushSizes <- kPartitions (n - spineLen) spineLen
> bushes <- traverse spinyTrees bushSizes
> return $ buildSpine (reverse bushes)
>
> buildSpine :: [Tree] -> Tree
> buildSpine [] = Leaf
> buildSpine (b:bs) = Node (buildSpine bs) b
This appears to give us something reasonable:
ghci> size (spinyTrees 7) == size (enumTreesMemo 7)
True
But it’s pretty slow—which is to be expected with all those monadic operations required. And there’s more:
ghci> sorted . map brackets . enumerate $ spinyTrees 3
True
ghci> sorted . map brackets . enumerate $ spinyTrees 4
True
ghci> sorted . map brackets . enumerate $ spinyTrees 5
False
Foiled again! All we did was stave off failure a bit, until 
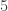
The solution: just forget about trees, already
It finally occurred to me that there was nothing in the problem statement that said anything about trees. That was just something my overexcited combinatorial brain imposed on it: obviously, since there is a bijection between balanced bracketings and binary trees, we should think about binary trees, right? …well, there is also a bijection between balanced bracketings and permutations avoiding (231), and lattice paths that stay above the main diagonal, and hundreds of other things, so… not necessarily.
In this case, I think trees just end up making things harder. Let’s think instead about enumerating balanced bracket sequences directly. To do it recursively, we need to know how to enumerate possible endings to the start of any balanced bracket sequence. That is, we need to enumerate sequences containing 

Given this idea, the code is fairly straightforward:
> enumBrackets :: Int -> Enumeration String
> enumBrackets n = enumBracketsTail n 0
>
> enumBracketsTail :: Int -> Int -> Enumeration String
> enumBracketsTail = memo2 enumBracketsTail'
> where
To enumerate a sequence with no opening brackets, just generate c closing brackets.
> enumBracketsTail' 0 c = singleton (replicate c ')')
To enumerate balanced sequences with
> enumBracketsTail' n 0 = ('(':) <$> enumBracketsTail (n-1) 1
In general, a sequence with (n-1, c+1)-sequence, or a closing bracket followed by an (n, c-1)-sequence.
> enumBracketsTail' n c =
> (('(':) <$> enumBracketsTail (n-1) (c+1))
> ++
> ((')':) <$> enumBracketsTail n (c-1))
This is quite fast, and as a quick check, it does indeed seem to give us the same size enumerations as the other tree enumerations:
ghci> fromNat (enumBrackets 40) 16221270422764920820
"((((((((()((())()(()()()())(()))((()()()()(()((()())))((()())))))))()))()())()))"
ghci> size (enumBrackets 100) == size (enumTreesMemo 100)
True
But, are they sorted? It would seem so!
ghci> all sorted (map (enumerate . enumBrackets) [1..10])
True
At this point, you might notice that this can be easily de-abstracted into a fairly simple dynamic programming solution, using a 2D array to keep track of the size of the enumeration for each (n,c) pair. I’ll leave the details to interested readers.


A friend that just finished his Physics degree said to me yesterday that it would take him more time to solve a first-semester problem than it would after the first semester, because today he has more tools he needs to choose between.
Knowing nothing about bijections to trees or permutations or whatever, I immediately thought about enumerations that can be indexed.
My first attempt was based on the idea that
solutions 0 = ""
solutions 2 = "()"
solutions n =
["(" ++ x ++ ")" ++ y | x <- solutions (n - 2), y <- solutions 0] ++
["(" ++ x ++ ")" ++ y | x <- solutions (n - 4), y <- solutions 2] ++
...
["(" ++ x ++ ")" ++ y | x <- solutions 0, y <- solutions (n - 2)]
However, this idea turned out to be wrong (they were not sorted correctly for N=8).
I then thought about it some more and figured out the much simpler rule (basically your solution):
solutions n = solutions' n 0
solutions' n open | open n = []
solutions' n open | n == open = ')' : solutions (n-1) (n-1) -- just an optimization
solutions' n open = ['(':x | x <- solutions (n - 1) (open + 1)] ++ [')':x | x <- solutions (n - 1) (open - 1)]
A Python solution was very easy to write and very short, my only issue with it being that it reflects the rule twice, once for counts and once for actually generating a solution at an index:
COUNT = {(0, 0): 1}
def count(unassigned, open):
assert unassigned >= 0, unassigned
assert (unassigned + open) % 2 == 0, (unassigned, open)
if open unassigned:
return 0
if open == unassigned:
return 1
x = (unassigned, open)
if x not in COUNT:
COUNT[x] = count(unassigned - 1, open + 1) + count(unassigned - 1, open - 1)
return COUNT[x]
def mth(n, m_human):
return _mth(n, 0, m_human - 1)
def _mth(unassigned, open, index):
assert 0 <= index <= count(unassigned, open)
if unassigned == open:
return ')' * unassigned
unassigned -= 1
open += 1
c = count(unassigned, open)
if index < c:
return '(' + _mth(unassigned, open, index)
index -= c
open -= 2
return ')' + _mth(unassigned, open, index)
for i in xrange(0, 16, 2):
items = []
for j in xrange(count(i, 0)):
x = mth(i, j + 1)
items.append(x)
for item in items:
print item
assert list(sorted(items)) == items, items
Here is a solution that only contains the rule once:
class Union(object): def __init__(self, *sublists): self.sublists = sublists def __len__(self): if not hasattr(self, 'size'): self.size = sum(len(sub) for sub in self.sublists) return self.size def __getitem__(self, index): i = index for sub in self.sublists: if i < len(sub): return sub[i] i -= len(sub) raise KeyError(index) class Transformation(object): def __init__(self, items, func): self.items = items self.func = func def __len__(self): return len(self.items) def __getitem__(self, index): return self.func(self.items[index]) class Solution(object): def __init__(self): self.cache = {} def solve(self, n, m): return self.build(n, 0)[m - 1] def build(self, *args): if args not in self.cache: self.cache[args] = self._build(*args) return self.cache[args] OPEN = staticmethod(lambda x: '(' + x) CLOSE = staticmethod(lambda x: ')' + x) def _build(self, free, open): if open free: return () elif open == free: return (')' * free,) return Union( Transformation(self.build(free - 1, open + 1), self.OPEN), Transformation(self.build(free - 1, open - 1), self.CLOSE) ) solution = Solution() for i in xrange(0, 16, 2): items = [] for j in xrange(len(solution.build(i, 0))): x = solution.solve(i, j + 1) items.append(x) for item in items: print item assert list(sorted(items)) == items, itemsPingback: Lightweight, efficiently sampleable enumerations in Haskell | blog :: Brent -> [String]
Pingback: Competitive programming in Haskell: Enumeration | blog :: Brent -> [String]