
> {-# LANGUAGE TypeFamilies, EmptyDataDecls, TypeOperators, GADTs #-}
At the end of his most recent blog post, Divided Differences and the Tomography of Types, Dan Piponi left his readers with a challenge:
In preparation for the next installment, here’s a problem to think about: consider the tree type above. We can easily build trees whose elements are of type A or of type B. We just need f(A+B). We can scan this tree from left to right building a list of elements of type A+B, ie. whose types are each either A or B. How can we redefine the tree so that the compiler enforces the constraint that at no point in the list, the types of four elements in a row spell the word BABA? Start with a simpler problem, like enforcing the constraint that AA never appears.
The tree type Dan is referring to is this one:
> data F a = Leaf a | Form (F a) (F a)
This is the type of binary trees with data at the leaves, also sometimes referred to as the type of parenthesizations.
(By the way, I highly recommend reading Dan’s whole post, which is brilliant; unfortunately, to really grok it you’ll probably want to first read his previous post Finite Differences of Types and Conor McBride’s Clowns to the Left of Me, Jokers to the Right.)
For now let’s focus on the suggested warmup, to enforce that AA never appears. For example, the following tree is OK:
> tree1 = Form (Form (Leaf (Right 'x'))
> (Leaf (Left 1)))
> (Leaf (Right 'y'))
because the types of the elements at its leaves form the sequence BAB. However, we would like to rule out trees like
> tree2 = Form (Form (Leaf (Right 'x'))
> (Leaf (Left 1)))
> (Leaf (Left 2))
which contains the forbidden sequence AA.
Checking strings to see if they contain forbidden subexpressions… sounds like a job for regular expressions and finite state automata! First, we write down a finite state automaton which checks for strings not containing AA:

A finite state machine for strings avoiding AA
State 0 is the starting state; the blue circles represent accepting states and the red circle is a rejecting state. (I made this one by hand, but of course there are automatic methods for generating such automata given a regular expression.)
The idea now — based on another post by Dan — is to associate with each tree a transition function 

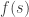
There’s a twist, of course, due to that little phrase "compiler enforces the constraint"… we have to do all of this at the type level! Well, I’m not afraid of a little type-level computation, are you?
First, type-level naturals, and some aliases for readability:
> data Z
> data S n
>
> type S0 = Z
> type S1 = S Z
> type S2 = S (S Z)
We’ll use natural numbers to represent FSM states. Now, how can we represent transition functions at the type level? We certainly can’t represent functions in general. But transition functions are just maps from the (finite) set of states to itself, so we can represent one just by enumerating its outputs 
> data Nil
> data (x ::: xs)
> infixr 5 :::
And a list indexing function:
> type family (n :!! l) :: *
> type instance ((x ::: xs) :!! Z) = x
> type instance ((x ::: xs) :!! S n) = xs :!! n
(Did you know you could have infix type family operators? I didn’t. I just tried it and it worked!)
Finally, we need a way to compose transition functions. If f1 and f2 are transition functions, then f1 :>>> f2 is the transition function you get by doing first f1 and then f2. This is not hard to compute: we just use each element of f1 in turn as an index into f2.
> type family (f1 :>>> f2) :: *
> type instance (Nil :>>> f2) = Nil
> type instance ((s ::: ss) :>>> f2) = (f2 :!! s) ::: (ss :>>> f2)
Great! Now we can write down a type of trees with two leaf types and a phantom type index indicating the FSM transition function for the tree.
> data Tree' a b f where
A tree containing only an A sends state 0 to state 1 and both remaining states to state 2:
> LeafA :: a -> Tree' a b (S1 ::: S2 ::: S2 ::: Nil)
A tree containing only a B sends states 0 and 1 to state 0, and leaves state 2 alone:
> LeafB :: b -> Tree' a b (S0 ::: S0 ::: S2 ::: Nil)
Finally, we compose trees by composing their transition functions:
> Branch :: Tree' a b f1 -> Tree' a b f2 -> Tree' a b (f1 :>>> f2)
For the final step, we simply note that valid trees are those which send state 0 (the starting state) to either state 0 or state 1 (state 2 means we saw an AA somewhere). We existentially quantify over the rest of the transition functions because we don’t care what the tree does if the FSM starts in some state other than the starting state.
> data Tree a b where
> T0 :: Tree' a b (S0 ::: ss) -> Tree a b
> T1 :: Tree' a b (S1 ::: ss) -> Tree a b
Does it work? We can write down our example tree with a BAB structure just fine:
*Main> :t T0 $ Branch (Branch (LeafB 'x') (LeafA 1)) (LeafB 'y')
T0 $ Branch (Branch (LeafB 'x') (LeafA 1)) (LeafB 'y')
:: (Num a) => Tree a CharBut if we try to write down the other example, we simply can’t:
*Main> :t T0 $ Branch (Branch (LeafB 'x') (LeafA 1)) (LeafA 2)
:1:5:
Couldn't match expected type `Z' against inferred type `S (S Z)'
...
*Main> :t T1 $ Branch (Branch (LeafB 'x') (LeafA 1)) (LeafA 2)
:1:5:
Couldn't match expected type `Z' against inferred type `S Z'
...It’s a bit annoying that for any given tree we have to know whether we ought to use T0 or T1 as the constructor. However, if we kept a bit more information around at the value level, we could write smart constructors leafA :: a -> Tree a b, leafB :: b -> Tree a b, and branch :: Tree a b -> Tree a b -> Maybe (Tree a b) which would take care of this for us; I leave this as an exercise.
This solution can easily be adapted to solve the original problem of avoiding BABA (or any regular expression). All that would need to be changed are the types of LeafA and LeafB, to encode the transitions in an appropriate finite state machine.
This has been fun, but I can’t help thinking there must be a cooler and more direct way to do it. I’m looking forward to Dan’s next post with eager anticipation:
Matrices of types have another deeper and surprising interpretation that will allow me to unify just about everything I’ve ever said on automatic differentiation, divided differences, and derivatives of types as well as solve a wide class of problems relating to building data types with certain constraints on them. I’ll leave that for my next article.
If that’s not a teaser, I don’t know what is!


Very nice! Conceptually your solution is isomorphic to mine but you use very different type-level datastructures to get there. Actually, your code is more elegant than mine. But I tried to write something more general so I could do the unification I claimed. I’ll see if I can get something finished this weekend before you guess what I’m going to write next. :-)
I’ve also not been keeping up with Haskell extensions for type-level programming. So reading your post will probably allow me to remove some of the old-fashioned type classes I’ve been using. So thanks!
Thanks! At this point I am quite clueless as to the connection between this and matrices of types, so I look forward to seeing how it all fits together.
As for type-level programming, the biggest thing is using type families instead of multi-parameter type classes, which often makes things much clearer. You may be interested in reading this post, which is basically a mini-tutorial on using type families for type-level programming.