
On the #haskell IRC channel a week or so ago, cdsmithus asked:
An easy (hopefully) question. I have an infinite list. How do I get a list of ordered pairs of stuff from the first list?
Several people suggested variations on the following theme:
pairs = [(b,a-b) | a <- [0..], b <- [0..a]]
which produces the list pairs = [(0,0), (0,1), (1,0), (0,2), (1,1), (2,0), (0,3), (1,2), (2,1), (3,0), ... I’m not sure if this was exactly the solution cdsmithus wanted, but just to humor me, let’s suppose it was. =) In a sense, this can be considered a “universal” sort of solution, since given any infinite list xs :: [a], we can get a corresponding list of pairs from xs by evaluating
map (\(a,b) -> (xs!!a, xs!!b)) pairs
But of course this isn’t very efficient, since (xs!!a) is O(a) — the beginning of xs is getting unnecessarily traversed over and over again. So, can we do this in a more “direct” way?
Notice the similarity to power series multiplication: multiplying the general power series 

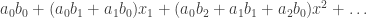
Both are instances of discrete convolution. I immediately thought of Douglas McIlroy’s classic Functional Pearl, Power Series, Power Serious. In it, he exhibits some amazing, simple, elegant Haskell code for computing with power series, treated as infinite (lazy!) lists of coefficients. The part we’re interested in is the definition of lazy power series multiplication:
(f:fs) * (g:gs) = f*g : (f.*gs + g.*fs + (0 : fs*gs))
where x .* ys = map (x*) ys, essentially. This code may seem mysterious, but any confusion is quickly cleared up by the simple algebraic derivation:

So, can we adapt this to compute list convolutions instead of numeric power series convolutions? Sure! We just need to make a few adjustments. First, we’ll replace element-wise multiplication with the tupling operator (,). And instead of addition, we’ll use list concatenation to collect tupled results. Finally, since tupling and concatenation are not commutative like multiplication and addition, we’ll have to be a bit more careful about order. There are a few other minor issues, but I’ll just let the code speak for itself:
import Prelude hiding ((+),(*),(**)) import qualified Prelude as P (+) = zipWith (++) x * y = [(x,y)] x .* ys = map (x*) ys ys *. x = map (*x) ys (**) :: [a] -> [b] -> [[(a,b)]] [] ** _ = [] _ ** [] = [] (x:xs) ** (y:ys) = x*y : (x .* ys) + ([] : (xs ** ys)) + (xs *. y)
We can test it out in ghci (being sure to pass ghci the -fno-implicit-prelude option so we don’t get conflicts with our definition of (**)):
> take 10 . concat $ [1..] ** ['a'..] [(1,'a'),(1,'b'),(2,'a'),(1,'c'),(2,'b'),(3,'a'),(1,'d'),(2,'c'),(3,'b'),(4,'a')] > take 10 . concat $ [0..] ** [0..] [(0,0),(0,1),(1,0),(0,2),(1,1),(2,0),(0,3),(1,2),(2,1),(3,0)]
Cool! Now, there’s just one issue left: this code is still rather slow, because of the way it uses list concatenation repeatedly to accumulate results; in fact, I suspect that it ends up being not much better, speed-wise, than the naive code we looked at first which generates numeric tuples and then indexes into the lists! Taking the first one million elements of concat $ [1..] ** [1..], multiplying each pair, and summing the results takes around 16 seconds on my machine.
We can easily fix this up by using “difference lists” instead of normal lists: we represent a list xs by the function (xs++). Then list concatenation is just function composition — O(1) instead of O(n). Kenn Knowles wrote about this representation recently, and Don Stewart has written the dlist package implementing it. We don’t require a whole fancy package just for this application, however; the changes are easy enough to make:
import Prelude hiding ((+),(*),(**)) import qualified Prelude as P type List a = [a] -> [a] fromList :: [a] -> List a fromList = (++) toList :: List a -> [a] toList = ($[]) singleton :: a -> List a singleton = (:) empty :: List a empty = id (+) = zipWith (.) x * y = singleton (x,y) x .* ys = map (x*) ys ys *. x = map (*x) ys (**) :: [a] -> [b] -> [List (a,b)] [] ** _ = [] _ ** [] = [] (x:xs) ** (y:ys) = x*y : (x .* ys) + (empty : (xs ** ys)) + (xs *. y)
Ah, much better. This code only takes 0.6 seconds on my machine to compute the same result with the first one million elements of concat . map toList $ [1..] ** [1..].

