tl;dr: How to compile a functional language via combinators (and evaluate via the Haskell runtime) while keeping the entire process type-indexed, with a bibliography and lots of references for further reading
There is a long history, starting with Schönfinkel and Curry, of abstracting away variable names from lambda calculus terms by converting to combinators, aka bracket abstraction. This was popular in the 80’s as a compilation technique for functional languages (Turner, 1979; Augustsson, 1986; Jones, 1987; Diller, 1988), then apparently abandoned. More recently, however, it has been making a bit of a comeback. For example, see Naylor (2008), Gratzer (2015), Lynn (2017), and Mahler (2021). Bracket abstraction is intimately related to compiling to cartesian closed categories (Elliott, 2017; Mahler, 2021), and also enables cool tricks like doing evaluation via the Haskell runtime system (Naylor, 2008; Seo, 2016; Mahler, 2022).
However, it always bothered me that the conversion to combinators was invariably described in an untyped way. Partly to gain some assurance that we are doing things correctly, but mostly for fun, I wondered if it would be possible to do the whole pipeline in an explicitly type-indexed way. I eventually found a nice paper by Oleg Kiselyov (2018) which explains exactly how to do it (it even came with OCaml code that I was easily able to port to Haskell!).
In this blog post, I:
- Show an example of typechecking and elaboration for a functional language into explicitly type-indexed terms, such that it is impossible to write down ill-typed terms
- Demonstrate a Haskell port of Oleg Kiselyov’s typed bracket abstraction algorithm
- Demonstrate type-indexed evaluation of terms via the Haskell runtime
- Put together an extensive bibliography with references for further reading
This blog post is rendered automatically from a literate Haskell file; you can find the complete working source code and blog post on GitHub. I’m always happy to receive comments, fixes, or suggestions for improvement.
So many yummy language extensions.
{-# LANGUAGE ConstraintKinds #-}
{-# LANGUAGE DataKinds #-}
{-# LANGUAGE ExplicitForAll #-}
{-# LANGUAGE FlexibleContexts #-}
{-# LANGUAGE GADTs #-}
{-# LANGUAGE ImportQualifiedPost #-}
{-# LANGUAGE InstanceSigs #-}
{-# LANGUAGE KindSignatures #-}
{-# LANGUAGE LambdaCase #-}
{-# LANGUAGE OverloadedStrings #-}
{-# LANGUAGE PatternSynonyms #-}
{-# LANGUAGE RankNTypes #-}
{-# LANGUAGE StandaloneDeriving #-}
{-# LANGUAGE TypeApplications #-}
{-# LANGUAGE TypeFamilies #-}
{-# LANGUAGE TypeOperators #-}
{-# LANGUAGE UnicodeSyntax #-}
{-# LANGUAGE ViewPatterns #-}
module TypedCombinators where
import Control.Monad.Combinators.Expr
import Data.Functor.Const qualified as F
import Data.Void
import Data.Text ( Text )
import Data.Text qualified as T
import Data.Kind (Type)
import Data.Type.Equality ( type (:~:)(Refl), TestEquality(..) )
import Text.Megaparsec
import Text.Megaparsec.Char
import Text.Megaparsec.Char.Lexer qualified as L
import Witch (into)
import Prelude hiding (lookup)
Raw terms and types
Here’s an algebraic data type to represent raw terms of our DSL, something which might come directly out of a parser. The exact language we use here isn’t all that important; I’ve put in just enough features to make it nontrivial, but not much beyond that. We have integer literals, variables, lambdas, application, let and if expressions, addition, and comparison with >. Of course, it would be easy to add more types, constants, and language features.
data Term where
Lit :: Int -> Term
Var :: Text -> Term
Lam :: Text -> Ty -> Term -> Term
App :: Term -> Term -> Term
Let :: Text -> Term -> Term -> Term
If :: Term -> Term -> Term -> Term
Add :: Term -> Term -> Term
Gt :: Term -> Term -> Term
deriving Show
A few things to note:
-
In order to keep things simple, notice that lambdas must be annotated with the type of the argument. There are other choices we could make, but this is the simplest for now. I’ll have more to say about other choices later.
-
I included if not only because it gives us something to do with Booleans, but also because it is polymorphic, which adds an interesting twist to our typechecking.
-
I included >, not only because it gives us a way to produce Boolean values, but also because it uses ad-hoc polymorphism, that is, we can compare at any type which is an instance of Ord. This is an even more interesting twist.
Here are our types: integers, booleans, and functions.
data Ty where
TyInt :: Ty
TyBool :: Ty
TyFun :: Ty -> Ty -> Ty
deriving Show
Finally, here’s an example term that uses all the features of our language (I’ve included a simple parser in an appendix at the end of this post):
example :: Term
example = readTerm $ T.unlines
[ "let twice = \\f:Int -> Int. \\x:Int. f (f x) in"
, "let z = 1 in"
, "if 7 > twice (\\x:Int. x + 3) z then z else z + 1"
]
Since 7 is not, in fact, strictly greater than 1 + 3 + 3, this should evaluate to 2.
Type-indexed constants
That was the end of our raw, untyped representations—from now on, everything is going to be type-indexed! First of all, we’ll declare an enumeration of constants, with each constant indexed by its corresponding host language type. These will include both any special language built-ins (like if, +, and >) as well as a set of combinators which we’ll be using as a compilation target—more on these later.
data Const :: Type -> Type where
CInt :: Int -> Const Int
CIf :: Const (Bool -> α -> α -> α)
CAdd :: Const (Int -> Int -> Int)
CGt :: Ord α => Const (α -> α -> Bool)
I :: Const (α -> α)
K :: Const (α -> b -> α)
S :: Const ((α -> b -> c) -> (α -> b) -> α -> c)
B :: Const (( b -> c) -> (α -> b) -> α -> c)
C :: Const ((α -> b -> c) -> b -> α -> c)
deriving instance Show (Const α)
The polymorphism of if (and the combinators I, K, etc., for that matter) poses no real problems. If we really wanted the type of CIf to be indexed by the exact type of if, it would be something like
CIf :: Const (∀ α. Bool -> α -> α -> α)
but this would require impredicative types which can be something of a minefield. However, what we actually get is
CIf :: ∀ α. Const (Bool -> α -> α -> α)
which is unproblematic and works just as well for our purposes.
The type of CGt is more interesting: it includes an Ord α constraint. That means that at the time we construct a CGt value, we must have in scope an Ord instance for whatever type α is; conversely, when we pattern-match on CGt, we will bring that instance into scope. We will see how to deal with this later.
For convenience, we make a type class HasConst for type-indexed things that can contain embedded constants (we will end up with several instances of this class).
class HasConst t where
embed :: Const α -> t α
Also for convenience, here’s a type class for type-indexed things that support some kind of application operation. (Note that we don’t necessarily want to require t to support a pure :: a -> t a operation, or even be a Functor, so using Applicative would not be appropriate, even though $$ has the same type as <*>.)
infixl 1 $$
class Applicable t where
($$) :: t (α -> β) -> t α -> t β
Note that, unlike the standard $ operator, $$ is left-associative, so, for example, f $$ x $$ y should be read just like f x y, that is, f $$ x $$ y = (f $$ x) $$ y.
Finally, we’ll spend a bunch of time applying constants to things, or applying things to constants, so here are a few convenience operators for combining $$ and embed:
infixl 1 .$$
(.$$) :: (HasConst t, Applicable t) => Const (α -> β) -> t α -> t β
c .$$ t = embed c $$ t
infixl 1 $$.
($$.) :: (HasConst t, Applicable t) => t (α -> β) -> Const α -> t β
t $$. c = t $$ embed c
infixl 1 .$$.
(.$$.) :: (HasConst t, Applicable t) => Const (α -> β) -> Const α -> t β
c1 .$$. c2 = embed c1 $$ embed c2
Type-indexed types and terms
Now let’s build up our type-indexed core language. First, we’ll need a data type for type-indexed de Bruijn indices. A value of type Idx γ α is a variable with type α in the context γ (represented as a type-level list of types). For example, Idx [Int,Bool,Int] Int would represent a variable of type Int (and hence must either be variable 0 or 2).
data Idx :: [Type] -> Type -> Type where
VZ :: Idx (α ': γ) α
VS :: Idx γ α -> Idx (β ': γ) α
deriving instance Show (Idx γ α)
Now we can build our type-indexed terms. Just like variables, terms are indexed by a typing context and a type; t : TTerm γ α can be read as “t is a term with type α, possibly containing variables whose types are described by the context γ”. Our core language has only variables, constants, lambdas, and application. Note we’re not just making a type-indexed version of our original term language; for simplicity, we’re going to simultaneously typecheck and elaborate down to this much simpler core language. (Of course, it would also be entirely possible to introduce another intermediate data type for type-indexed terms, and separate the typechecking and elaboration phases.)
data TTerm :: [Type] -> Type -> Type where
TVar :: Idx γ α -> TTerm γ α
TConst :: Const α -> TTerm γ α
TLam :: TTerm (α ': γ) β -> TTerm γ (α -> β)
TApp :: TTerm γ (α -> β) -> TTerm γ α -> TTerm γ β
deriving instance Show (TTerm γ α)
instance Applicable (TTerm γ) where
($$) = TApp
instance HasConst (TTerm γ) where
embed = TConst
Now for some type-indexed types!
data TTy :: Type -> Type where
TTyInt :: TTy Int
TTyBool :: TTy Bool
(:->:) :: TTy α -> TTy β -> TTy (α -> β)
deriving instance Show (TTy ty)
TTy is a term-level representation of our DSL’s types, indexed by corresponding host language types. In other words, TTy is a singleton: for a given type α there is a single value of type TTy α. Put another way, pattern-matching on a value of type TTy α lets us learn what the type α is. (See (Le, 2017) for a nice introduction to the idea of singleton types.)
We will need to be able to test two value-level type representations for equality and have that reflected at the level of type indices; the TestEquality class from Data.Type.Equality is perfect for this. The testEquality function takes two type-indexed things and returns a type equality proof wrapped in Maybe.
instance TestEquality TTy where
testEquality :: TTy α -> TTy β -> Maybe (α :~: β)
testEquality TTyInt TTyInt = Just Refl
testEquality TTyBool TTyBool = Just Refl
testEquality (α₁ :->: β₁) (α₂ :->: β₂) =
case (testEquality α₁ α₂, testEquality β₁ β₂) of
(Just Refl, Just Refl) -> Just Refl
_ -> Nothing
testEquality _ _ = Nothing
Recall that the CGt constant requires an Ord instance; the checkOrd function pattern-matches on a TTy and witnesses the fact that the corresponding host-language type has an Ord instance (if, in fact, it does).
checkOrd :: TTy α -> (Ord α => r) -> Maybe r
checkOrd TTyInt r = Just r
checkOrd TTyBool r = Just r
checkOrd _ _ = Nothing
As a quick aside, for simplicity’s sake, I am going to use Maybe throughout the rest of this post to indicate possible failure. In a real implementation, one would of course want to return more information about any error(s) that occur.
Existential wrappers
Sometimes we will need to wrap type-indexed things inside an existential wrapper to hide the type index. For example, when converting from a Ty to a TTy, or when running type inference, we can’t know in advance which type we’re going to get. So we create the Some data type which wraps up a type-indexed thing along with a corresponding TTy. Pattern-matching on the singleton TTy will allow us to recover the type information later.
data Some :: (Type -> Type) -> Type where
Some :: TTy α -> t α -> Some t
mapSome :: (∀ α. s α -> t α) -> Some s -> Some t
mapSome f (Some α t) = Some α (f t)
The first instantiation we’ll create is an existentially wrapped type, where the TTy itself is the only thing we care about, and the corresponding t will just be the constant unit type functor. It would be annoying to keep writing F.Const () everywhere so we create some type and pattern synonyms for convenience.
type SomeTy = Some (F.Const ())
pattern SomeTy :: TTy α -> SomeTy
pattern SomeTy α = Some α (F.Const ())
{-# COMPLETE SomeTy #-}
The someType function converts from a raw Ty to a type-indexed TTy, wrapped up in an existential wrapper.
someType :: Ty -> SomeTy
someType TyInt = SomeTy TTyInt
someType TyBool = SomeTy TTyBool
someType (TyFun a b) = case (someType a, someType b) of
(SomeTy α, SomeTy β) -> SomeTy (α :->: β)
Type inference and elaboration
Now that we have our type-indexed core language all set, it’s time to do type inference, that is, translate from untyped terms to type-indexed ones! First, let’s define type contexts, i.e. mappings from variables to their types. We store contexts simply as a (fancy, type-indexed) list of variable names paired with their types. This is inefficient—it takes linear time to do a lookup—but we don’t care, because this is an intermediate representation used only during typechecking. By the time we actually get around to running terms, variables won’t even exist any more.
data Ctx :: [Type] -> Type where
-- CNil represents an empty context.
CNil :: Ctx '[]
-- A cons stores a variable name and its type,
-- and then the rest of the context.
(:::) :: (Text, TTy α) -> Ctx γ -> Ctx (α ': γ)
Now we can define the lookup function, which takes a variable name and a context and tries to return a corresponding de Bruijn index into the context. When looking up a variable name in the context, we can’t know in advance what index we will get and what type it will have, so we wrap the returned Idx in Some.
lookup :: Text -> Ctx γ -> Maybe (Some (Idx γ))
lookup _ CNil = Nothing
lookup x ((y, α) ::: ctx)
| x == y = Just (Some α VZ)
| otherwise = mapSome VS <$> lookup x ctx
Now we’re finally ready to define the infer function! It takes a type context and a raw term, and tries to compute a corresponding type-indexed term. Note that there’s no particular guarantee that the term we return corresponds to the input term—we will just have to be careful—but at least the Haskell type system guarantees that we can’t return a type-incorrect term, which is especially important when we have some nontrivial elaboration to do. Of course, just as with variable lookups, when inferring the type of a term we can’t know in advance what type it will have, so we will need to return an existential wrapper around a type-indexed term.
infer :: Ctx γ -> Term -> Maybe (Some (TTerm γ))
infer ctx = \case
To infer the type of a literal integer value, just return TTyInt with a literal integer constant.
Lit i -> return $ Some TTyInt (embed (CInt i))
To infer the type of a variable, look it up in the context and wrap the result in TVar. Notice how we are allowed to pattern-match on the Some returned from lookup (revealing the existentially quantified type inside) since we immediately wrap it back up in another Some when returning the TVar.
Var x -> mapSome TVar <$> lookup x ctx
To infer the type of a lambda, we convert the argument type annotation to a type-indexed type, infer the type of the body under an extended context, and then return a lambda with an appropriate function type. (If lambdas weren’t required to have type annotations, then we would either have to move the lambda case to the check function, or else use unification variables and solve type equality constraints. The former would be straightforward, but I don’t know how to do the latter in a type-indexed way—sounds like a fun problem for later.)
Lam x a t -> do
case someType a of
Some α _ -> do
Some β t' <- infer ((x,α) ::: ctx) t
return $ Some (α :->: β) (TLam t')
To infer the type of an application, we infer the type of the left-hand side, ensure it is a function type, and check that the right-hand side has the correct type. We will see the check function later.
App t1 t2 -> do
Some τ t1' <- infer ctx t1
case τ of
α :->: β -> do
t2' <- check ctx α t2
return $ Some β (TApp t1' t2')
_ -> Nothing
To infer the type of a let-expression, we infer the type of the definition, infer the type of the body under an extended context, and then desugar it into an application of a lambda. That is, let x = t1 in t2 desugars to (\x.t2) t1.
Let x t1 t2 -> do
Some α t1' <- infer ctx t1
Some β t2' <- infer ((x, α) ::: ctx) t2
return $ Some β (TApp (TLam t2') t1')
Note again that we can’t accidentally get mixed up here—for example, if we incorrectly desugar to (\x.t1) t2 we get a Haskell type error, like this:
• Couldn't match type ‘γ’ with ‘α : γ’
Expected: TTerm γ α1
Actual: TTerm (α : γ) α1
To infer an if-expression, we can check that the test has type Bool, infer the types of the two branches, and ensure that they are the same. If so, we return the CIf constant applied to the three arguments. The reason this typechecks is that pattern-matching on the Refl from the testEquality call brings into scope the fact that the types of t2 and t3 are equal, so we can apply CIf which requires them to be so.
If t1 t2 t3 -> do
t1' <- check ctx TTyBool t1
Some α t2' <- infer ctx t2
Some β t3' <- infer ctx t3
case testEquality α β of
Nothing -> Nothing
Just Refl -> return $ Some α (CIf .$$ t1' $$ t2' $$ t3')
Addition is simple; we just check that both arguments have type Int.
Add t1 t2 -> do
t1' <- check ctx TTyInt t1
t2' <- check ctx TTyInt t2
return $ Some TTyInt (CAdd .$$ t1' $$ t2')
“Greater than” is a bit interesting because we allow it to be used at both Int and Bool. So, just as with if, we must infer the types of the arguments and check that they match. But then we must also use the checkOrd function to ensure that the argument types are an instance of Ord. In particular, we wrap CGt (which requires an Ord constraint) in a call to checkOrd α (which provides one).
Gt t1 t2 -> do
Some α t1' <- infer ctx t1
Some β t2' <- infer ctx t2
case testEquality α β of
Nothing -> Nothing
Just Refl -> (\c -> Some TTyBool (c .$$ t1' $$ t2')) <$> checkOrd α CGt
Finally, here’s the check function: to check that an expression has an expected type, just infer its type and make sure it’s the one we expected. (With more interesting languages we might also have more cases here for terms which can be checked but not inferred.) Notice how this also allows us to return the type-indexed term without using an existential wrapper, since the expected type is an input.
check :: Ctx γ -> TTy α -> Term -> Maybe (TTerm γ α)
check ctx α t = do
Some β t' <- infer ctx t
case testEquality α β of
Nothing -> Nothing
Just Refl -> Just t'
Putting this all together so far, we can check that the example term has type Int and see what it elaborates to (I’ve included a simple pretty-printer for TTerm in an appendix):
λ> putStrLn . pretty . fromJust . check CNil TTyInt $ example
(λ. (λ. if (gt 7 (x1 (λ. plus x0 3) x0)) x0 (plus x0 1)) 1) (λ. λ. x1 (x1 x0))
An aside: a typed interpreter
We can now easily write an interpreter. However, this is pretty inefficient (it has to carry around an environment and do linear-time variable lookups), and later we’re going to compile our terms directly to host language terms. So this interpreter is just a nice aside, for fun and testing.
With that said, given a closed term, we can interpret it directly to a value of its corresponding host language type. We need typed environments and a indexing function (note that for some reason GHC can’t see that the last case of the indexing function is impossible; if we tried implementing it in, say, Agda, we wouldn’t have to write that case).
data Env :: [Type] -> Type where
ENil :: Env '[]
ECons :: α -> Env γ -> Env (α ': γ)
(!) :: Env γ -> Idx γ α -> α
(ECons x _) ! VZ = x
(ECons _ e) ! (VS x) = e ! x
ENil ! _ = error "GHC can't tell this is impossible"
Now the interpreter is straightforward. Look how beautifully everything works out with the type indexing.
interpTTerm :: TTerm '[] α -> α
interpTTerm = go ENil
where
go :: Env γ -> TTerm γ α -> α
go e = \case
TVar x -> e ! x
TLam body -> \x -> go (ECons x e) body
TApp f x -> go e f (go e x)
TConst c -> interpConst c
interpConst :: Const α -> α
interpConst = \case
CInt i -> i
CIf -> \b t e -> if b then t else e
CAdd -> (+)
CGt -> (>)
K -> const
S -> (<*>)
I -> id
B -> (.)
C -> flip
λ> interpTTerm . fromJust . check CNil TTyInt $ example
2
Compiling to combinators: type-indexed bracket abstraction
Now, on with the main attraction! It’s well-known that certain sets of combinators are Turing-complete: for example, SKI is the most well-known complete set (or just SK if you’re trying to be minimal). There are well-known algorithms for compiling lambda calculus terms into combinators, known generally as bracket abstraction (for further reading about bracket abstraction in general, see Diller (2014); for some in-depth history along with illustrative Haskell code, see Ben Lynn’s page on Combinatory Logic (2022); for nice example implementations in Haskell, see blog posts by Gratzer (2015), Seo (2016), and Mahler (2021).)
So the idea is to compile our typed core language down to combinators. The resulting terms will have no lambdas or variables—only constants and application! The point is that by making environments implicit, with a few more tricks we can make use of the host language runtime’s ability to do beta reduction, which will be much more efficient than our interpreter.
The BTerm type below will be the compilation target. Again for illustration and/or debugging we can easily write a direct interpreter for BTerm—but this still isn’t the intended code path. There will still be one more step to convert BTerms directly into host language terms.
data BTerm :: Type -> Type where
BApp :: BTerm (α -> β) -> BTerm α -> BTerm β
BConst :: Const α -> BTerm α
deriving instance Show (BTerm ty)
instance Applicable BTerm where
($$) = BApp
instance HasConst BTerm where
embed = BConst
interpBTerm :: BTerm ty -> ty
interpBTerm (BApp f x) = interpBTerm f (interpBTerm x)
interpBTerm (BConst c) = interpConst c
We will use the usual SKI combinators as well as B and C, which are like special-case variants of S:
S x y z = x z (y z)B x y z = x (y z)C x y z = x z (y )
S handles the application of x to y in the case where they both need access to a shared parameter z; B and C are similar, but B is used when only y, and not x, needs access to z, and C is for when only x needs access to z. Using B and C will allow for more efficient encodings than would be possible with S alone. If you want to compile a language with recursion you can also easily add the usual Y combinator (“SICKBY”), although the example language in this post has no recursion so we won’t use it.
Bracket abstraction is often presented in an untyped way, but I found this really cool paper by Oleg Kiselyov (2018) where he shows how to do bracket abstraction in a completely compositional, type-indexed way. I found the paper a bit hard to understand, but fortunately it came with working OCaml code! Translating it to Haskell was straightforward. Much later, after writing most of this blog post, I found a a nice explanation of Kiselyov’s paper by Lynn (2022) which helped me make more sense of the paper.
First, a data type for open terms, which represent an intermediate stage in the bracket abstraction algorithm, where some parts have been converted to closed combinator terms (the E constructor embeds BTerm values), and some parts still have not. This corresponds to Kiselyov’s eta-optimized version (section 4.1 of the paper). A simplified version that does not include V is possible, but results in longer combinator expressions.
data OTerm :: [Type] -> Type -> Type where
-- E contains embedded closed (i.e. already abstracted) terms.
E :: BTerm α -> OTerm γ α
-- V represents a reference to the innermost/top environment
-- variable, i.e. Z
V :: OTerm (α ': γ) α
-- N represents internalizing the innermost bound variable as a
-- function argument. In other words, we can represent an open
-- term referring to a certain variable as a function which
-- takes that variable as an argument.
N :: OTerm γ (α -> β) -> OTerm (α ': γ) β
-- For efficiency, there is also a special variant of N for the
-- case where the term does not refer to the topmost variable at
-- all.
W :: OTerm γ β -> OTerm (α ': γ) β
instance HasConst (OTerm γ) where
embed = E . embed
Now for the bracket abstraction algorithm. First, a function to do type- and environment-preserving conversion from TTerm to OTerm. The conv function handles the variable, lambda, and constant cases. The application case is handled by the Applicable instance.
conv :: TTerm γ α -> OTerm γ α
conv = \case
TVar VZ -> V
TVar (VS x) -> W (conv (TVar x))
TLam t -> case conv t of
V -> E (embed I)
E d -> E (K .$$ d)
N e -> e
W e -> K .$$ e
TApp t1 t2 -> conv t1 $$ conv t2
TConst c -> embed c
The Applicable instance for OTerm has 15 cases—one for each combination of OTerm constructors. Why not 16, you ask? Because the V $$ V case is impossible (exercise for the reader: why?). The cool thing is that GHC can tell that case would be ill-typed, and agrees that this definition is total—that is, it does not give a non-exhaustive pattern match warning. This is a lot of code, but understanding each individual case is not too hard if you understand the meaning of the constructors E, V, N, and W. For example, if we have one term that ignores the innermost bound variable being applied to another term that also ignores the innermost bound variable (W e1 $$ W e2), we can apply one term to the other and wrap the result in W again (W (e1 $$ e2)). Other cases use the combinators B, C, S to route the input to the proper places in an application.
instance Applicable (OTerm γ) where
($$) :: OTerm γ (α -> β) -> OTerm γ α -> OTerm γ β
W e1 $$ W e2 = W (e1 $$ e2)
W e $$ E d = W (e $$ E d)
E d $$ W e = W (E d $$ e)
W e $$ V = N e
V $$ W e = N (E (C .$$. I) $$ e)
W e1 $$ N e2 = N (B .$$ e1 $$ e2)
N e1 $$ W e2 = N (C .$$ e1 $$ e2)
N e1 $$ N e2 = N (S .$$ e1 $$ e2)
N e $$ V = N (S .$$ e $$. I)
V $$ N e = N (E (S .$$. I) $$ e)
E d $$ N e = N (E (B .$$ d) $$ e)
E d $$ V = N (E d)
V $$ E d = N (E (C .$$. I $$ d))
N e $$ E d = N (E (C .$$. C $$ d) $$ e)
E d1 $$ E d2 = E (d1 $$ d2)
The final bracket abstraction algorithm consists of calling conv on a closed TTerm—this must result in a term of type OTerm '[] α, and the only constructor which could possibly produce such a type is E, containing an embedded BTerm. So we can just extract that BTerm, and GHC can see that this is total.
bracket :: TTerm '[] α -> BTerm α
bracket t = case conv t of { E t' -> t' }
Let’s apply this to our example term and see what we get:
λ> putStrLn . pretty . bracket . fromJust . check CNil TTyInt $ example
C C 1 (C C (C C 1 plus) (B S (C C I (B S (B (B if) (B (B (gt 7)) (C I (C C 3 plus)))))))) (S B I)
λ> interpBTerm . bracket . fromJust . check CNil TTyInt $ example
2
Neat! This is not too much longer than the original term, which is the point of using the optimized version. Interestingly, this example happens to not use K at all, but a more complex term certainly would.
Kiselyov also presents an even better algorithm using  -ary combinators which uses guaranteed linear time and space. For simplicity, he presents it in an untyped way and claims in passing that it “can be backported to the typed case”, though I am not aware of anyone who has actually done this yet (perhaps I will, later). Lynn (2022) has a nice explanation of Kiselyov’s paper, including a section that explores several alternatives to Kiselyov’s linear-time algorithm.
-ary combinators which uses guaranteed linear time and space. For simplicity, he presents it in an untyped way and claims in passing that it “can be backported to the typed case”, though I am not aware of anyone who has actually done this yet (perhaps I will, later). Lynn (2022) has a nice explanation of Kiselyov’s paper, including a section that explores several alternatives to Kiselyov’s linear-time algorithm.
Compiling type-indexed combinators to Haskell
So at this point we can take a Term, typecheck it to produce a TTerm, then use bracket abstraction to convert that to a BTerm. We have an interpreter for BTerms, but we’re instead going to do one more compilation step, to turn BTerms directly into native Haskell values. This idea originates with Naylor (2008) and is well-explained in blog posts by Seo (2016) and Mahler (2022). This still feels a little like black magic to me, and I am actually unclear on whether it is really faster than calling interpBTerm; some benchmarking would be needed. In any case I include it here for completeness.
Our target for this final compilation step is the following CTerm type, which has only functions, represented by CFun, and constants. Note, however, that CConst is intended to be used only for non-function types, i.e. base types, although there’s no nice way (that I know of, at least) to use the Haskell type system to enforce this.
data CTerm α where
CFun :: (CTerm α -> CTerm β) -> CTerm (α -> β)
CConst :: α -> CTerm α -- CConst invariant: α is not a function type
instance Applicable CTerm where
CFun f $$ x = f x
CConst _ $$ _ = error "CConst should never contain a function!"
compile :: BTerm α -> CTerm α
compile (BApp b1 b2) = compile b1 $$ compile b2
compile (BConst c) = compileConst c
compileConst :: Const α -> CTerm α
compileConst = \case
(CInt i) -> CConst i
CIf -> CFun $ \(CConst b) -> CFun $ \t -> CFun $ \e -> if b then t else e
CAdd -> binary (+)
CGt -> binary (>)
K -> CFun $ \x -> CFun $ \_ -> x
S -> CFun $ \f -> CFun $ \g -> CFun $ \x -> f $$ x $$ (g $$ x)
I -> CFun id
B -> CFun $ \f -> CFun $ \g -> CFun $ \x -> f $$ (g $$ x)
C -> CFun $ \f -> CFun $ \x -> CFun $ \y -> f $$ y $$ x
binary :: (α -> b -> c) -> CTerm (α -> b -> c)
binary op = CFun $ \(CConst x) -> CFun $ \(CConst y) -> CConst (op x y)
Finally, we can “run” a CTerm α to extract a value of type α. Typically, if α is some kind of base type like Int, runCTerm doesn’t actually do any work—all the work is done by the Haskell runtime itself. However, for completeness, I include a case for CFun as well.
runCTerm :: CTerm α -> α
runCTerm (CConst a) = a
runCTerm (CFun f) = runCTerm . f . CConst
We can put this all together into our final pipeline:
evalInt :: Term -> Maybe Int
evalInt = fmap (runCTerm . compile . bracket) . check CNil TTyInt
λ> evalInt example
Just 2
Appendices
There’s nothing interesting to see here—unless you’ve never written a parser or pretty-printer before, in which case perhaps it is very interesting! If you want to learn how to write parsers, see this very nice Megaparsec tutorial. And see here for some help writing a basic pretty-printer.
Parsing
type Parser = Parsec Void Text
type ParserError = ParseErrorBundle Text Void
reservedWords :: [Text]
reservedWords = ["let", "in", "if", "then", "else", "Int", "Bool"]
sc :: Parser ()
sc = L.space space1 (L.skipLineComment "--") empty
lexeme :: Parser a -> Parser a
lexeme = L.lexeme sc
symbol :: Text -> Parser Text
symbol = L.symbol sc
reserved :: Text -> Parser ()
reserved w = (lexeme . try) $ string' w *> notFollowedBy alphaNumChar
identifier :: Parser Text
identifier = (lexeme . try) (p >>= nonReserved) <?> "variable name"
where
p = (:) <$> letterChar <*> many alphaNumChar
nonReserved (into @Text -> t)
| t `elem` reservedWords =
fail . into @String $
T.concat ["reserved word '", t, "' cannot be used as variable name"]
| otherwise = return t
integer :: Parser Int
integer = lexeme L.decimal
parens :: Parser a -> Parser a
parens = between (symbol "(") (symbol ")")
parseTermAtom :: Parser Term
parseTermAtom =
Lit <$> integer
<|> Var <$> identifier
<|> Lam <$> (symbol "\\" *> identifier)
<*> (symbol ":" *> parseType)
<*> (symbol "." *> parseTerm)
<|> Let <$> (reserved "let" *> identifier)
<*> (symbol "=" *> parseTerm)
<*> (reserved "in" *> parseTerm)
<|> If <$> (reserved "if" *> parseTerm)
<*> (reserved "then" *> parseTerm)
<*> (reserved "else" *> parseTerm)
<|> parens parseTerm
parseTerm :: Parser Term
parseTerm = makeExprParser parseTermAtom
[ [InfixL (App <$ symbol "")]
, [InfixL (Add <$ symbol "+")]
, [InfixL (Gt <$ symbol ">")]
]
parseTypeAtom :: Parser Ty
parseTypeAtom =
TyInt <$ reserved "Int"
<|> TyBool <$ reserved "Bool"
<|> parens parseType
parseType :: Parser Ty
parseType = makeExprParser parseTypeAtom
[ [InfixR (TyFun <$ symbol "->")] ]
readTerm :: Text -> Term
readTerm = either undefined id . runParser parseTerm ""
Pretty-printing
type Prec = Int
class Pretty p where
pretty :: p -> String
pretty = prettyPrec 0
prettyPrec :: Prec -> p -> String
prettyPrec _ = pretty
mparens :: Bool -> String -> String
mparens True = ("("++) . (++")")
mparens False = id
instance Pretty (Const α) where
prettyPrec _ = \case
CInt i -> show i
CIf -> "if"
CAdd -> "plus"
CGt -> "gt"
c -> show c
instance Pretty (Idx γ α) where
prettyPrec _ = ("x" ++) . show . toNat
where
toNat :: Idx γ α -> Int
toNat VZ = 0
toNat (VS i) = 1 + toNat i
instance Pretty (TTerm γ α) where
prettyPrec p = \case
TVar x -> pretty x
TConst c -> pretty c
TLam t -> mparens (p>0) $ "λ. " ++ prettyPrec 0 t
TApp t1 t2 -> mparens (p>1) $
prettyPrec 1 t1 ++ " " ++ prettyPrec 2 t2
instance Pretty (BTerm α) where
prettyPrec p = \case
BConst c -> pretty c
BApp t1 t2 -> mparens (p>0) $
prettyPrec 0 t1 ++ " " ++ prettyPrec 1 t2
References
Augustsson, L. (1986) SMALL: A small interactive functional system. Chalmers Tekniska Högskola/Göteborgs Universitet. Programming Methodology Group.
Diller, A. (1988) Compiling functional languages. John Wiley & Sons, Inc.
Diller, A. (2014)
Bracket abstraction algorithms. Available at:
https://www.cantab.net/users/antoni.diller/brackets/intro.html.
Elliott, C. (2017) ‘Compiling to categories’, Proceedings of the ACM on Programming Languages, 1(ICFP), pp. 1–27.
Gratzer, D. (2015)
Bracket Abstraction: The Smallest PL You’ve Ever Seen. Available at:
https://jozefg.bitbucket.io/posts/2015-05-01-brackets.html.
Jones, S.L.P. (1987) The Implementation of Functional Programming Languages. Prentice-Hall, Inc.
Kiselyov, O. (2018) ‘λ to ski, semantically: Declarative pearl’, in International symposium on functional and logic programming. Springer, pp. 33–50.
Le, J. (2017)
Introduction to Singletons (Part 1). Available at:
https://blog.jle.im/entry/introduction-to-singletons-1.html.
Lynn, B. (2017)
A Combinatory Compiler. Available at:
https://crypto.stanford.edu/~blynn/lambda/sk.html.
Lynn, B. (2022)
Combinatory Logic. Available at:
https://crypto.stanford.edu/~blynn/lambda/cl.html.
Lynn, B. (2022)
Kiselyov Combinator Translation. Available at:
https://crypto.stanford.edu/~blynn/lambda/kiselyov.html.
Naylor, M. (2008) ‘Evaluating Haskell in Haskell’, The Monad.Reader. Edited by W. Swierstra, Issue 10.
Turner, D.A. (1979) ‘A new implementation technique for applicative languages’, Software: Practice and Experience, 9(1), pp. 31–49.



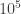 ”, which would be a standard sort of condition for a combinatorics problem, but that’s not quite the same thing, in a very annoying way: for example, if the answer is
”, which would be a standard sort of condition for a combinatorics problem, but that’s not quite the same thing, in a very annoying way: for example, if the answer is  , we are supposed to output
, we are supposed to output 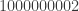 , we are supposed to output
, we are supposed to output ![s[0 \dots n-1]](https://s0.wp.com/latex.php?latex=s%5B0+%5Cdots+n-1%5D&bg=ffffff&fg=333333&s=0&c=20201002) be the given string, and let
be the given string, and let 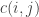 be the number of ways to turn the substring
be the number of ways to turn the substring ![s[i \dots j-1]](https://s0.wp.com/latex.php?latex=s%5Bi+%5Cdots+j-1%5D&bg=ffffff&fg=333333&s=0&c=20201002) into a properly nested sequence of brackets, so ultimately we want to compute the value of
into a properly nested sequence of brackets, so ultimately we want to compute the value of 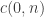 . (Note we make
. (Note we make  but excludes
but excludes  , which means, for example, that the length of the substring is
, which means, for example, that the length of the substring is 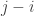 .) First, some base cases:
.) First, some base cases: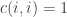 since the empty string always counts as properly nested.
since the empty string always counts as properly nested. if
if ![s[i]](https://s0.wp.com/latex.php?latex=s%5Bi%5D&bg=ffffff&fg=333333&s=0&c=20201002) had better be an opening bracket of some kind, and we can try matching it with each of
had better be an opening bracket of some kind, and we can try matching it with each of ![s[i+1]](https://s0.wp.com/latex.php?latex=s%5Bi%2B1%5D&bg=ffffff&fg=333333&s=0&c=20201002) ,
, ![s[i+3]](https://s0.wp.com/latex.php?latex=s%5Bi%2B3%5D&bg=ffffff&fg=333333&s=0&c=20201002) ,
, ![s[i+5]](https://s0.wp.com/latex.php?latex=s%5Bi%2B5%5D&bg=ffffff&fg=333333&s=0&c=20201002) , …,
, …, ![s[j-1]](https://s0.wp.com/latex.php?latex=s%5Bj-1%5D&bg=ffffff&fg=333333&s=0&c=20201002) . In general, matching
. In general, matching ![s[k]](https://s0.wp.com/latex.php?latex=s%5Bk%5D&bg=ffffff&fg=333333&s=0&c=20201002) can be done in either
can be done in either  ,
,  , or
, or  ways depending on whether they are proper opening and closing brackets and whether any question marks are involved; then we have
ways depending on whether they are proper opening and closing brackets and whether any question marks are involved; then we have 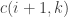 ways to make the substring between
ways to make the substring between 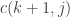 ways for the rest of the string following
ways for the rest of the string following ![c(i,j) = \begin{cases} 1 & i = j \\ 0 & i \not \equiv j \pmod 2 \\ \displaystyle \sum_{k \in [i+1, i+3, \dots, j-1]} m(s[i], s[k]) \cdot c(i+1,k) \cdot c(k+1,j) & \text{otherwise} \end{cases}](https://s0.wp.com/latex.php?latex=c%28i%2Cj%29+%3D+%5Cbegin%7Bcases%7D+1+%26+i+%3D+j+%5C%5C+0+%26+i+%5Cnot+%5Cequiv+j+%5Cpmod+2+%5C%5C+%5Cdisplaystyle+%5Csum_%7Bk+%5Cin+%5Bi%2B1%2C+i%2B3%2C+%5Cdots%2C+j-1%5D%7D+m%28s%5Bi%5D%2C+s%5Bk%5D%29+%5Ccdot+c%28i%2B1%2Ck%29+%5Ccdot+c%28k%2B1%2Cj%29+%26+%5Ctext%7Botherwise%7D+%5Cend%7Bcases%7D&bg=ffffff&fg=333333&s=0&c=20201002)
 counts the number of ways to make
counts the number of ways to make  and
and  into a matching pair of brackets: it returns 0 if the two characters cannot possibly be a matching open-close pair (either because they do not match or because one of them is the wrong way around); 1 if they match, and at most one of them is a question mark; and 3 if both are question marks.
into a matching pair of brackets: it returns 0 if the two characters cannot possibly be a matching open-close pair (either because they do not match or because one of them is the wrong way around); 1 if they match, and at most one of them is a question mark; and 3 if both are question marks.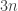 which has
which has  different parses. If we fed this string to the
different parses. If we fed this string to the 
 , but with a twist. We are given a list of
, but with a twist. We are given a list of  , and a single string describing a number, consisting of concatenated digit names. For example, if
, and a single string describing a number, consisting of concatenated digit names. For example, if 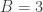 and the names of the digits are
and the names of the digits are 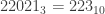 . Crucially, we are also told that the digit names are prefix-free, that is, no digit name is a prefix of any other. But other than that, the digit names could be really weird: they could be very different lengths, some digit names could occur as substrings (just not prefixes) of others, digit names could share common prefixes, and so on. So this is really more of a parsing problem than a math problem; once we have parsed the string as a list of digits, converting from base
. Crucially, we are also told that the digit names are prefix-free, that is, no digit name is a prefix of any other. But other than that, the digit names could be really weird: they could be very different lengths, some digit names could occur as substrings (just not prefixes) of others, digit names could share common prefixes, and so on. So this is really more of a parsing problem than a math problem; once we have parsed the string as a list of digits, converting from base 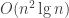 time in the worst case (I think)—but this is actually fine since
time in the worst case (I think)—but this is actually fine since  time.
time.