
BlogLiterately is a tool for uploading blog posts to servers that support the MetaWeblog API (such as WordPress-based blogs and many others). Blog posts to be published via BlogLiterately are written in markdown or reStructuredText format, with extensions supported by pandoc. Posts may be actual “bird-style” literate Haskell files, with commentary formatted using markdown or reStructuredText. Though BlogLiterately offers special support for literate Haskell in particular, it is also useful for writing posts including code written in other languages, or even no code at all. You may also be interested in the BlogLiterately-diagrams package, a plugin for BlogLiterately which allows embedding images in your posts defined using the diagrams vector graphics framework.
BlogLiterately includes support for syntax highlighting, 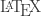
ghci sessions. Each of these features is explained in more detail below.
Example usage
If you do not specify a blog URL, by default BlogLiterately simply prints the generated HTML to stdout. So, to preview the generated HTML before uploading requires merely something like
BlogLiterately Sample.lhsTo actually post to, say, a WordPress blog, a basic command line would be something like
BlogLiterately --blog http://blogurl.example.com/xmlrpc.php \
--user myname --password mypasswd --title "Sample" Sample.lhs(which creates a new post). You can also omit the --password option, in which case BlogLiterately will prompt you for your password.
If the post ID of that post (which BlogLiterately prints when it uploads a new post) is ‘37’, then to update the post, the command would be something like
BlogLiterately --postid 37 --blog http://blogurl.example.com/xmlrpc.php \
--user myname --password mypasswd --title "Sample" Sample.lhsand the post will be updated with the new text. In both cases the post is uploaded as a draft. To publish the post, you can pass the --publish option (or, of course, you can flip the publish bit manually on the server).
The above examples only show the most basic usage. In particular, the pain of constructing long command lines like the above is unnecessary, and can be replaced by the use of profiles and embedding options within the source file itself; these features are explained below.
Markdown and pandoc
BlogLiterately can take as input files written using the markdown format (as well as reStructuredText). See the markdown website for detailed documentation. BlogLiterately uses pandoc for reading markdown, which also supports a few extensions to the basic format.
By default, BlogLiterately assumes that markdown files should be parsed as if they contain literate Haskell code. To disable processing of markdown files with literate Haskell extensions, use the --no-lit-haskell command-line argument. This makes a difference, for example, when processing paragraphs set off by “bird tracks” (i.e. leading > characters): in literate Haskell, these are code blocks, whereas in plain markdown they are blockquotes. In addition, section headings beginning with hash signs (#, ##, etc.) cannot be used in literate Haskell mode; only section headings underlined with hyphens or equals signs are supported.
Determining input format
BlogLiterately takes the following steps to determine whether an input file is in markdown or reStructuredText format:
-
If the format is explicitly specified on the command line with
--format=markdownor--format=rst, the specified format will be used regardless of the file name. -
Otherwise, the filename extension is consulted: if it is
.rst,.rest, or.txt, reStructuredText will be assumed; otherwise, markdown is assumed.
Code blocks and syntax highlighting
Code segments (including actual source lines from literate haskell files, as well as markdown or reStructuredText code blocks) may be syntax highlighted. Two different syntax highlighting libraries are supported:
- hscolour is specifically for syntax highlighting of Haskell code, and is the standard highlighter used on Hackage and elsewhere.
- highlighting-kate is a general syntax highlighting library that can be used for highlighting a wide range of languages (including Haskell).
You may independently specify whether to use hscolour or highlighting-kate to highlight Haskell code; other languages will be highlighted with highlighting-kate.
In basic markdown, a generic code block is set off from normal text by indenting at least four spaces:
-- This is a code segment, but what language is it?
foo :: String -> StringSimilarly, in reStructuredText, a code block is constructed by a double colon followed by an indented block:
::
-- This is a code segment, but what language is it?
foo :: String -> StringHowever, markdown does not have a way of specifying the language used in a code block, making support for syntax highlighting problematic. Pandoc offers an alternative syntax for code segments which does allow specifying the language:
~~~~ { .haskell }
-- This is a Haskell code segment!
foo :: String -> String
~~~~The above syntax works only with markdown. BlogLiterately also supports one additional style which works with both markdown and reStructuredText, consisting of a normal code block (indented and/or preceded by a double colon) with an extra tag at the top, enclosed in square brackets:
[haskell]
-- This is also a Haskell code segment!
foo :: String -> StringOf course, languages other than Haskell may be specified as well.
By default, hscolour will be used for highlighting Haskell code, using “inline” CSS style attributes. The default styling is similar to that used for source code in documentation on Hackage. You can also specify a configuration file containing a Haskell value of type [(String,String)] which specifies a CSS style for each syntax class. An example (corresponding to the default configuration) is provided in the package archive (hs-style).
With highlighting-kate, the style for syntax segments is specified using “class” attributes, so the stylesheet must be provided separately. You may optionally use a similar scheme with hscolour. Sample stylesheets are provided in the package archive file (kate.css, hscolour.css).
Citations
BlogLiterately can take advantage of pandoc’s ability to process and typeset citations. To include citations in your blog post:
-
Specify a bibliography—either the name of a bibliography file, or an explicit list of references—as metadata in your document. With Markdown, this is accomplished with a YAML document enclosed by
---at the beginning of the file (see the Pandoc documentation on YAML metadata blocks). For example,--- title: My Blog Post bibliography: references.bib --- Foo bar [@doe2006].(There is no support yet for citations if you are using reStructuredText; yell if you want it.) You can specify the name of a file containing a bibliography, as in the example above; here is a list of the bibliography formats that are accepted. Alternately, you can give an explicit list of references.
-
Include citations, formatted like
[@doe2006]for a normal citation like (Doe, 2006);@doe2006for a text citation like Doe (2006), or[-@doe2006]for a citation without the name (for situations when the name already occurred elsewhere in the sentence). See the pandoc documentation for more details and examples. -
Simply run
BlogLiterately; citation processing is on by default. (You can explicitly turn it on with the--citationsflag; to turn it off, use--no-citations.) Citations will be typeset and a bibliography will be appended at the end. You may want to include a section heading like# Referencesor# Bibliographyat the end of your post, to go above the generated bibliography.
LaTeX
LaTeX can be included in documents using single dollar signs to enclose inline LaTeX, and double dollar signs to enclose “display-style” LaTeX. For example, $\pi^2 / 6$ produces 
$$\sum_{k=0}^\infty 1/k^2$$ (when put by itself in its own paragraph) produces

Using the --math option, any Pandoc math rendering method may be chosen, including MathML, jsMath, MathJax, and others. Note that for some methods to work properly, you may need to ensure that the generated HTML ends up in the proper CSS or JavaScript environment. (What that means depends on the method used.)
Alternatively, blogs hosted on wordpress.com have built-in support for LaTeX, compiling LaTeX expressions to embedded images on-the-fly. Passing the --wplatex option to BlogLiterately causes any embedded LaTeX to be output in the format expected by WordPress. Note that an extra $latex... won’t be added to the beginning of LaTeX expressions which already appear to be in WordPress format.
Finally, to simply pass LaTeX math through unchanged (for example, if your blog hosting software will do LaTeX processing), you can use the --rawlatex option.
Special links
Certain special link types can be replaced with appropriate URLs. A special link is one where the URL is of the form <name>::<text> where <name> is used to identify the special link type, and <text> is passed as a parameter to a function which can use it to generate a URL. Currently, four types of special links are supported by default (and you can easily add your own):
lucky::<search>
: The first Google result for <search>.
wiki::<title>
: The Wikipedia page for <title>. (Note that the page is not checked for existence.)
post::nnnn
: Link to the blog post on your blog with post ID nnnn. Note that this form of special link is invoked when nnnn consists of all digits, so it only works on blogs which use numerical identifiers for post IDs (as WordPress does).
post::<search>
: Link to the most recent blog post (among the 20 most recent posts) containing <search> in its title.
For example, a post written in Markdown format containing
This is a post about the game of [Go](wiki::Go (game)).
will be formatted in HTML as
<p>This is a post about the game of <a href="https://en.wikipedia.org/wiki/Go%20(game)">Go</a>.</p>
You can easily add your own new types of special links. See the SpecialLink type and the mkSpecialLinksXF function.
Table of contents
BlogLiterately can also take advantage of pandoc’s ability to generate a table of contents. Just pass the --toc option to BlogLiterately and a table of contents will be added to the top of your post. See this documentation itself for an example of the output.
ghci sessions
When writing literate Haskell documents, it is often useful to show a sample ghci session illustrating the behavior of the code being described. However, manually pasting in the results of sample sessions is tedious and error-prone, and it can be difficult keeping sample sessions “in sync” when making changes to the code.
For these reasons, BlogLiterately supports special [ghci] code blocks, consisting of a list of Haskell expressions (or, more generally, arbitrary ghci commands), one per line. These expressions/commands are evaluated using ghci, and the results typeset along with the original expressions in the output document. The entire literate Haskell document itself will be loaded into ghci before evaluating the expressions, so expressions may reference anything in scope. Note also that all expressions in the entire document will be evaluated in the same ghci session, so names bound with let or <- will also be in scope in subsequent expressions, even across multiple [ghci] blocks.
For example, consider the following definition:
> hailstone x
> | even x = x `div` 2
> | otherwise = 3*x + 1
Now, given the input
[ghci]
:t hailstone
hailstone 15
takeWhile (/= 1) . iterate hailstone $ 7
txt <- readFile "BlogLiteratelyDoc.lhs"
length txtBlogLiterately generates the following output:
ghci> :t hailstone
hailstone :: Integral a => a -> a
ghci> hailstone 15
46
ghci> takeWhile (/= 1) . iterate hailstone $ 7
[7,22,11,34,17,52,26,13,40,20,10,5,16,8,4,2]
ghci> txt <- readFile "BlogLiteratelyDoc.lhs"
ghci> length txt
24540
(And yes, of course, the above output really was generated by BlogLiterately!) Additionally, lines indented by one or more spaces are interpreted as expected outputs instead of inputs. Consecutive indented lines are interpreted as one multi-line expected output, with a number of spaces removed from the beginning of each line equal to the number of spaces at the start of the first indented line.
If the output for a given input is the same as the expected output (or if no expected output is given), the result is typeset normally. If the actual and expected outputs differ, the actual output is typeset first in red, then the expected output in blue. For example,
[ghci]
reverse "kayak"
7+18
25
hailstone 15
107834produces
ghci> reverse "kayak"
"kayak"
ghci> 7+18
25
ghci> hailstone 15
46
107834
There are currently a few known limitations of this feature:
-
The code for interfacing with
ghciis not very robust. In particular, expressions which generate an error (e.g. ones which refer to an out-of-scope name, or do not typecheck) will simply lack any accompanying output; it would be much more useful to display the accompanying error message. -
If the literate document itself fails to load (e.g. due to improper formatting)
BlogLiteratelymay hang. -
The formatting of
ghcisessions currently cannot be customized. Suggestions for customizations to allow are welcome. -
Due to the very hacky way that
ghciinteraction is implemented, the usualitvariable bound to the result of the previous expression is not available (well, to be more precise, it is available… but is always equal to()).
Uploading embedded images
When passed the --upload-images option, BlogLiterately can take any images referenced locally and automatically upload them to the server, replacing the local references with appropriate URLs.
To include images in blog posts, use the Markdown syntax
(or the corresponding reStructuredText syntax).
The URL determines whether the image will be uploaded. A remote URL is any beginning with http or a forward slash (interpreted as a URL relative to the server root). In all other cases it is assumed that the URL in fact represents a relative path on the local file system. Such images, if they exist, will be uploaded to the server (using the metaWeblog.newMediaObject RPC call), and the local file name replaced with the URL returned by the server.
Uploaded images, and their associated server URLs, will be tracked in a file called .BlogLiterately-uploaded-images. A given image will only be uploaded once, even across multiple runs of BlogLiterately. In practice, this means that the --upload-images option can be left on while uploading multiple draft versions of a post, and only new images will be uploaded each time. Note, however, that images are tracked by file name, not contents, so modifications to an image (while leaving the name the same) will be ignored. As a workaround, delete .BlogLiterately-uploaded-images (or just the entry for the modified image), or give the modified image a different name.
A few caveats:
- The
newMediaObjectcall has an optionalreplaceparameter, butBlogLiteratelydoes not use it, since it’s too dangerous: ifreplaceis set and you happen to use the same file name as some other image file that already exists on your blog, the old image would be deleted. However, this means that if you upload an image multiple times you will get multiple copies on your blog. (Although this is mitigated somewhat by the mechanism to cache uploaded image URLs.)
Customization
It is possible to create your own variants of BlogLiterately which include custom processing steps. See the Text.BlogLiterately.Run module to get started.
Command-line options
Most of the command-line options for BlogLiterately are hopefully self-explanatory, given the above background:
BlogLierately v0.7, (c) Robert Greayer 2008-2010, Brent Yorgey 2012-2013
For help, see https://byorgey.wordpress.com/blogliterately/
BlogLiterately [OPTIONS] FILE
Common flags:
-s --style=FILE style specification (for --hscolour-icss)
--hscolour-icss highlight haskell: hscolour, inline style (default)
--hscolour-css highlight haskell: hscolour, separate stylesheet
--hs-nohighlight no haskell highlighting
--hs-kate highlight haskell with highlighting-kate
--kate highlight non-Haskell code with highlighting-kate
(default)
--no-kate don't highlight non-Haskell code
--lit-haskell parse as literate Haskell (default)
--no-lit-haskell do not parse as literate Haskell
--no-toc don't generate a table of contents (default)
--toc generate a table of contents
-r --rawlatex pass inline/display LaTeX through unchanged
-w --wplatex reformat inline LaTeX the way WordPress expects
-m --math=ITEM how to layout math, where
--math=[=URL]
-g --ghci run [ghci] blocks through ghci and include output
-I --upload-images upload local images
-C --category=ITEM post category (can specify more than one)
-T --tag=ITEM ---tags tag (can specify more than one)
--blogid=ID Blog specific identifier
-P --profile=STRING profile to use
-b --blog=URL blog XML-RPC url (if omitted, HTML goes to stdout)
-u --user=USER user name
-p --password=PASSWORD password
-t --title=TITLE post title
-f --format=FORMAT input format: markdown or rst
-i --postid=ID Post to replace (if any)
--page create a "page" instead of a post (WordPress only)
--publish publish post (otherwise it's uploaded as a draft)
-h --html-only don't upload anything; output HTML to stdout
--citations process citations (default)
--no-citations do not process citations
-x --xtra=ITEM extension arguments, for use with custom extensions
-? --help Display help message
-V --version Print version information
--numeric-version Print just the version numberProfiles
Certain options, such as --blog, --user, and --wplatex, may be the same for all your posts. You can create one or more profiles specifying a set of options, which can then be specified simply by referencing the profile, using the command-line option --profile/-P. For example, to use the profile named foo you would invoke
BlogLiterately -P foo ...(Alternately, you can also specify profile = foo within a [BLOpts] block in the source file itself; see the next section.)
The profile foo should be stored in a file named foo.cfg, and placed in the application directory for BlogLiterately: on POSIX systems, this means $HOME/.BlogLiterately/foo.cfg; on Windows, it typically means something like C:/Documents And Settings/user/Application Data/BlogLiterately/foo.cfg.
The profile should consist of a number of options, listed one per line, in the form
optionname = valueBoolean options are specified by true, on, false, or off. String values use normal Haskell syntax for strings, surrounded by double quotes. Optionally, the double quotes may be omitted for strings which do not contain spaces, double quotes, commas, or square brackets. Lists also use Haskell list syntax, with comma-separated items surrounded by square brackets, except that the square brackets may be omitted. For example, myblog.cfg might look like this:
blog = http://some.url/xmlrpc.php
user = joebloggs
password = f7430nvj!$4
wplatex = true
ghci = on
categories = foo, bar, "some really long category"The list of options which are currently supported are: style, lit-haskell, wplatex, math, ghci, upload-images, categories, tags, blogid, profile, blog, user, password, title, postid, page, publish, xtras.
Option blocks
In addition, options may be specified inline, using a code block marked with the [BLOpts]. For example,
[BLOpts]
profile = foo
title = "My awesome blog post!"
postid = 2000
tags = [awesome, stuff, blogging]
categories = [Writing, Stuff]
This is my awesome blog post. Here is some math: $\pi$, which will
get formatted for WordPress because I chose the `foo` profile
above, which includes `wplatex = true`.Such inline options use the same syntax as profiles, as described in the previous section.
Pandoc titles
Pandoc supports a special syntax for specifying the title, placing the title on the first line marked with %. BlogLiterately supports this format too, so the above example could also have been written as:
% My awesome blog post!
[BLOpts]
profile = foo
postid = 2000
...Generating HTML only
In the past, to get a “preview” version of the HTML output written to stdout, all you had to do was omit a --blog option. However, if you specify a profile with a blog field, this is more problematic. For this reason, a new option --html-only has been added. When this option is specified, nothing is uploaded, and the HTML output is written to stdout.
Getting Help
For questions, support, feature suggestions, etc., feel free to contact me (Brent Yorgey): byorgey on IRC (freenode), or byorgey at gmail. There is also a bug tracker where you can file bugs and feature requests.


Pingback: BlogLiterately 0.4 release « blog :: Brent -> [String]
In the current version there is one very small bug. :-P
The –help flag reports version 0.4 in the 0.5 release.
One question I have is how do you recommend viewing the post locally before uploading? I don’t see a flag for generating the post locally as a draft.
Cheers.
Haha, whoops, I’ll fix that in the next release.
If you do not specify a –blog option, by default it outputs the generated HTML to stdout. Perhaps it would be more obvious to have an explicit flag, with the ability to specify an output file.
It might be, or just add a comment to the documentation above noting that behavior.
Thanks for the quick reply.
The documentation above already does note that behavior, at the beginning of the “Example usage”. Is there somewhere else it should be mentioned as well? Where were you expecting to see something about it?
Oh you are right. Actually you note it in two different places. Sorry I just didn’t see it. I think where you have it is fine. I was just a clumsy reader.
Hi, Brent. I am not sure if there is a better place to discuss problems with your tool, but I have one more question.
When trying out your sample latex (from above): $$\sum_{k=0}^\infty 1/k^2$$ it seems that pandoc is converting the latex into unicode rather than the image you show above. Then unicode is then not interpretable by any of my browsers: Chrome, Fireforx, or Safari. Here is an image of the output: http://homepage.cs.uiowa.edu/~heades/Images/output.png
So it seems not much LaTex is working for me.
Well, the image is specifically being generated by WordPress, not by Pandoc. To get BlogLiterately to pass along the LaTeX uninterpreted by Pandoc so that WordPress can generate images, use the –wplatex option. Other than that I cannot really vouch for what Pandoc does with LaTeX, I tried to describe what I thought it does but I may be wrong. I’ve created a ticket for myself to look more carefully into this at some point and maybe add some MathJax support. The other option is to write a custom transformation pass to replace LaTeX with images using something like http://redsymbol.net/software/l2p/ .
I keep getting the same error (line numbers and everything) on several different files saying
BlogLiterately: user error (Error calling metaWeblog.newPost: in element tag html,
in element tag body,
in element tag div,
in element tag div,
in element tag div,
in element tag div,
in element tag article,
in element tag header,
in element tag div,
in element tag a,
missing = in attribute
at file string input at line 101 col 232)
This is probably not actually a problem with the tool, but I can’t figure out what I’m doing wrong.
Nevermind, I figured it out, careless mistake. I left out the /xmlrpc.php part of the url
Pingback: BlogLiterately 0.5.2 release, with improved image uploading | blog :: Brent -> [String]
Greetings Brent.
First off thank you for the effort you have put into BlogLiterately. I was able to install, with cabal, and run your package on my WinXP system yesterday. I had less luck on my Ubuntu 12.04 system and spent most of last night working through the package dependencies and building from source. Pandoc currently does not compile on Ubuntu which of course shafts your package. I’ll sort out the Linux build eventually – I consider it part of learning about Haskell.
As for the WinXP version. I was able to run and upload a test blog post from markdown source. Everything worked as expected except I could not get syntax highlighting working for languages other than Haskell. The version of pandoc compiled by the cabal WinXP install does highlight other languages so I believe I am missing something.
I am looking at your package to provide the backbone for syntax highlighting languages that WordPress.com does not support like J.
http://www.jsoftware.com/jwiki/FrontPage
Do you have any suggestions, examples or admonishments that might help?
Thanks again – John Baker
Hi John, thanks for the feedback, and glad you got BL to work on WinXP — and I hope Ubuntu will get things sorted out soon. A couple suggestions for you: (1) make sure you are calling BlogLiterately with the –highlight-other option. (Hmm, this should probably just be the default.) (2) By default what gets output is code marked up with span tags having class attributes indicating the syntax category of the thing wrapped in the span. That means that no syntax highlighting will be apparent unless you have an appropriate CSS file that specifies how to style the different syntax classes.
To be honest I haven’t really used the other-language-highlighting features much (if at all), and I’m they could be improved a lot. In particular I think there could be an option to do the same “baking in” of styles as is currently done for Haskell. I can look into that if you would be interested. But for now, see if having a CSS file solves the issue. For example, an appropriate CSS file can be found here: https://github.com/jgm/highlighting-kate/blob/master/css/hk-pyg.css
I have tried this with the following results. The pandoc highlighting span tags are present in supported languages. If you capture the HTML spit out by BlogLiterately and insert the CSS the highlighting turns on. How do you “attach” a CSS to BlogLiterately output during upload?
Haskell is clearly treated differently than other languages. You do not need to insert the CSS for Haskell highlighting to work.
PS. I have managed to extend pandoc by compiling in new highlighting xml files. Once I can build BlogLiterately with this pandoc+new languages I should be well down the road of being able to use your package to highlight languages other than Haskell.
Yes, currently there is no way to “attach” some CSS to the output. If you have access to the CSS settings for your blog you can simply modify your blog’s CSS to provide the correct environment so that your highlighted code renders properly. But there ought to be a way to have BlogLiterately “bake in” the styles if you specify a CSS file on the command line. I will try to look into this soon.
Thanks I will give this a try.
Pingback: Moving Again | Lab Notes
Hi Brent,
I like your approach. But why are you restricting to `html`-output? Couldn’t
you generate `markdown`, then going further to the desired output?
What I’m still missing is a general literate programming preprocessor, which
runs before `pandoc`.
Currently I use [knitr](https://github.com/yihui/knitr.git) a lot, where you
can also call foreign languages (meaning not `R`).
I would like a tool which could process, say a `lmd`-file:
% General literate programming
% Me, Myself
% Oct 2012
~~~.setup
fig.path = “figure”
~~~
Haskell
=======
~~~.ghci, label = hs-test, eval = True, echo = True
[x| x ] (P) to node {$f$} (B);
\draw[->] (P) to node [swap] {$g$} (A);
\draw[->] (A) to node [swap] {$f$} (C);
\draw[->] (B) to node {$g$} (C);
\draw[->, bend right] (P1) to node [swap] {$\hat{g}$} (A);
\draw[->, bend left] (P1) to node {$\hat{f}$} (B);
\draw[->, dashed] (P1) to node {$k$} (P);
\end{tikzpicture}
~~~
…
Which produces a markdown file like
% General literate programming
% Me, Myself
% Oct 2012
~~~.setup
fig.path = “figure”
~~~
Haskell
=======
~~~.haskell
[x| x <- [1..10], odd x]
— [1,3,5,7,9]
~~~
Tikz
====
An example from [cats](https://github.com/sdiehl/cats.git)

Just some thinking …
Pingback: Moving Again | Armchair Scientist
Hi, Brent. I think I have found a bug.
If I give BlogLiterately the following it outputs what you would expect:
”
However, if I give it the following input:
‘
‘
note the newline, then it outputs the following:
‘
‘
This I thought was strange. I am writing a very html/css heavy post and I noticed this.
Thanks,
Harley
Well that didn’t work.
Lets try this again. Read the previous comment, but see this file for the HTML:
http://metatheorem.org/wp-content/misc/test.bll
Hi Harley, thanks for the report. Unfortunately this seems to be a problem with pandoc’s markdown+lhs parser. For example you can see the problem already if you feed your input files to
pandoc -f markdown+lhs -t htmlinstead of to BlogLiterately. I should probably look into this at some point. In any case, another workaround that seems to do the trick is including a leading space on each line before HTML tags.I’ve created a ticket so I remember to look into this at some point: http://hub.darcs.net/byorgey/BlogLiterately/issue/9 .
Pingback: Beginning of wp2o2b | Functional Paradise
Pingback: BlogLiterately 0.6 | blog :: Brent -> [String]