
Suppose we have a sequence of slots indexed from 1 to 
- Given an index
, find the rightmost empty slot at or before index
We can also think of this in terms of two more fundamental operations:
- Mark a given index
- Given an index
such that
and
if there is no such
The simplest possible approach would be to use an array of booleans; then marking a slot full is trivial, and finding the rightmost empty slot before index
Can you think of a data structure to support both operations in 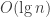
You can think of this in either functional or imperative terms. I know of two solutions, which I’ll share in a subsequent post, but I’m curious to see what people will come up with.
Note that in my scenario, slots never become empty again after becoming full. As an extra challenge, what if we relax this to allow setting slots arbitrarily?


Wouldn’t some sort of self-balancing search tree (e.g. Red-black tree) already solve this? Initialize it with all empty slots, then filling a slot is to delete it from the tree ( O(log n) for Red-black trees). Finding the biggest element smaller or equal i is also in O(log n). This would even give us “emptying” the slot for free by just re-inserting it
For a functional solution, use a normal search tree data structure (like `Int.Map`) and initially add all indices. To find the largest slot smaller than i, traverse looking for i. If i is there, great, that’s your j. If i is not there, because only _empty_ slots are in the tree, you should find the next-smallest empty slot. Maybe not the best constant factors, but seems to be logarithmic just nicely.
I can think of two techniques.
The Van Emde Boas construct is probably best when the total number of slots is known up front and is not going to change. Otherwise, a pair of self-balancing (e.g., AVL) trees should work: one keeps track of filled slots, the other of empty slots, each is indexed by by the slot number.
Proposed solution: Represent the sequence as a finger-tree. At each node in the tree, record two cached monoidal computation values: the total number of elements represented in the tree, and the total number of elements where proposition P(x) holds, where P = ’empty’ in this case.
When modifying the sequence – e.g. for insertion, deletion, split, concatenation, update – maintain these two values correctly. All of these operations are `O(lg(N))`.
To find an empty element below some index `i` within the tree, first split the tree to take the first `i` elements, then search for the rightmost node where number of `empty` elements is non-zero, while summing the total number of elements in nodes to the left (also `O(lg(N))`). The split and search could be combined into one function to avoid allocations on ‘split’.
This design has several nice features. In addition to allowing elements to become empty, it can efficiently represent large ‘sparse’ arrays via structure sharing, and size-changing insertions and deletions and concatenation of sequences.
It’s also easy to generalize to multiple propositions, e.g. if we had three boolean propositions on individual elements (like ’empty’ and ‘warning’ and ‘error’) then we simply need four counters per tree node (one for each proposition, plus total element count). We can also lazily zip sequences and maintain counts of propositions on the zipped elements.
Aside: We can efficiently maintain any monoidal computation over elements of a tree. Besides counting elements that match a boolean proposition, we could track min-values and max-values, sums and sums of squares, etc.. And boolean ‘or’ and ‘and’ is also monoidal. For simply finding the rightmost empty element, a boolean flag per node ‘contains at least one empty element’ would be sufficient. But I tend to use a counter instead of a boolean because it makes for very nice, efficient summaries and paged browsing.
A related challenge is extending this to ‘objects’ that take more than one slot – e.g. how do we find the first adjacent pair of empty slots? And perhaps generalize this further to 2D or 3D spaces.
By basing the structure on the Union-Find algorithm we can achieve O(α(n)) amortized time [worst case time is still O(ln(n))]. Each class contains a single empty slot and we store the index of that slot in the representative of the class. To mark an empty slot as full we union it’s class with the class of the slot immediately to the left. To find an empty slot we look up the representative of the slot at index `i`. I don’t think it’s possible to generalize this approach to support the case where full slots can become empty without breaking the O(α(n)) amortized time bound.
Example Implementation: https://play.rust-lang.org/?version=stable&mode=debug&edition=2018&gist=8c5cef6675f880465729922f3b56e277
An array of tuples. The first component is the number of free slots on the right and the second is a boolean with true for empty and false for full. The operation is similar to binary search:
find-and-update-rightmost (array : [(nat, bool)], i : nat, j : nat) {
// base case, when i == j or i == j – 1
let m : nat := (i+j)/2;
if (array[m][0] == 0 and array[m][1] == true) {
array[m][1] := false;
} else if (array[m][0] > 0) {
find-and-update-rightmost(array, m, j);
array[m][1]–;
} else {
find-and-update-rightmost(array, i, m);
}
}
I am quite sure the code is wrong on the indices, since I usually get that wrong with binary search. This pseudocode would need tweaking to make it run.
How do you maintain the ‘number of free slots on the right’?
I see you have `array[m][1] emdash`, which I assume was `minus-minus` after autocorrupt. But that should probably be `array[m][0]` because it’s your first component on the right. More importantly, you aren’t adjusting the number of free slots recorded to the right of `array[m-1]` or `array[m-2]` and so on, so won’t we have a bunch of incorrect counts for free slots to the right?
Great series on using Haskell to solve competition like problems!! I have been inspired by your writings to use Haskell for solving online judge problems. From my experiences so far, I find graph problems to be very inconvenient to solve in Haskell comparing to other type of problems, even dynamic programming. One of the biggest issue is that unlike imperative languages, there’s not “de facto/textbook” implementation for likes of DFS, BFS, etc using pure languages. I am aware of inductive graph, but it seems overly cumbersome to use for competitive problems. I would love to hear what your thoughts on solving graph problems using Haskell.
Hi, thanks for the comment, I’m glad my writing has inspired you! I completely agree that graph problems are inconvenient in Haskell. I always tend to use Java for anything involving graph algorithms. I, too, would love to figure out what the “right” way is to solve these types of problems in a pure functional language, and I hope to eventually write some blog posts on the topic. But first I’ve got a bunch of other ideas queued up — including a post about DP, which I actually find quite lovely in Haskell using lazy immutable arrays.
Looking forward to the future posts!! First time seeing how DP is done in lazy immutable array absolutely blows my mind.
Implicit binary heap. O(1) dereference, O(log n) mark, O(log n) find, O(log n) unmark. Define a custom type to indicate the emptiness of one or more of a slot’s children; indication of a slot’s emptiness propagates to all ancestors.
Array + doubly linked list. O(1) dereference, O(1) mark, O(1) find, O(1) unmark. The nodes of the doubly linked list consist of the empty slots of the sequence: each node holds an index, i, and has two links: the “left” link points to the node that represents the nearest empty slot less than i, and the “right” link points to the node that represents the nearest empty slot greater than i. Each element of the array consists of a pointer to the node in the doubly linked list that represents the empty slot less than or equal to that element’s index.
Dereferencing consists of following the pointer of a given index and determining if the given index and the index held by the node are the same. Marking a slot (as full) consists of removing the node with the given index from the doubly linked list and setting the pointer to point to the node at the removed node’s left link (if any). Finding a slot’s “rightmost empty slot” consists of following the pointer and returning the index held by the node if it is equal to the given index, otherwise, the index held by the node at the node’s left link (if any). Unmarking a slot (marking as empty) consists of creating a node holding the relevant index and inserting it into the doubly linked list to the right of the node indicated by the pointer, and updating the relevant pointer in the array accordingly.
“represents the empty slot” => “represents the nearest empty slot”
“updating the relevant pointer” => “updating the pointer”
I take this back. Broken pointers.
Too bad.
Pingback: Data structure challenge: solutions | blog :: Brent -> [String]
Pingback: Resumen de lecturas compartidas durante marzo de 2020 | Vestigium